
Nos dois artigos anteriores definimos o que é um conjunto e como operá-lo. Agora chegamos a uma pergunta natural: quantos elementos tem um conjunto? Essa pergunta simples esconde uma sutileza importante: quando dois conjuntos se sobrepõem e queremos contar a reunião, um simples \(n(A) + n(B)\) incorre em dupla contagem. O Princípio da Inclusão-Exclusão corrige isso — e é o primeiro resultado verdadeiramente combinatório desta série.
Cardinalidade #
A cardinalidade de um conjunto \(A\), denotada \(n(A)\) ou \(|A|\), é o número de elementos de \(A\).
Este artigo usa \(n(A)\) para evitar ambiguidade com o valor absoluto \(|x|\), que aparece nos exemplos a seguir. Na literatura de Ciência da Computação, porém, a notação \(|A|\) é a mais comum — você a encontrará em análise de algoritmos (\(O(|V| + |E|)\) em grafos, por exemplo) e em textos de combinatória e teoria dos conjuntos de nível universitário.
Dizemos que um conjunto é finito quando sua cardinalidade é um número natural. Quando a enumeração não termina, o conjunto é infinito (como \(\mathbb{N}\), \(\mathbb{Z}\), \(\mathbb{R}\)).
Exemplos
- \(A = \{x \in \mathbb{Z} \mid |x| \leq 3\} = \{-3,-2,-1,0,1,2,3\}\) → \(n(A) = 7\)
- \(B = \{x \in \mathbb{N} \mid x \text{ é par}\} = \{2,4,6,\ldots\}\) → infinito
- \(\emptyset\) → \(n(\emptyset) = 0\)
Vale notar que ser finito não significa ser fácil de contar. O conjunto de todas as pessoas nascidas antes do ano 2000 é finito, mas sua cardinalidade exata não está disponível de imediato. O que queremos são fórmulas que calculem cardinalidades a partir de dados mais simples.
Princípio Aditivo: Conjuntos Disjuntos #
Dois conjuntos são disjuntos quando não têm nenhum elemento em comum — precisamente quando \(A \cap B = \emptyset\). Esse conceito foi apresentado no artigo Diagramas de Venn e Operações; a figura abaixo o recapitula visualmente.
O caso mais simples de contagem ocorre quando os conjuntos são disjuntos: sem sobreposição, basta somar.
Se \(A \cap B = \emptyset\), então:
$$n(A \cup B) = n(A) + n(B)$$Generalizando: se \(A_1, A_2, \ldots, A_k\) são disjuntos dois a dois, então:
$$n(A_1 \cup A_2 \cup \cdots \cup A_k) = n(A_1) + n(A_2) + \cdots + n(A_k)$$A condição de disjunção é essencial. Quando há interseção, precisamos de uma fórmula mais cuidadosa.
Princípio da Inclusão-Exclusão #
Quando os conjuntos não são disjuntos, a simples soma \(n(A) + n(B)\) conta os elementos da interseção duas vezes. O Princípio da Inclusão-Exclusão (PIE) corrige isso de forma sistemática: soma os tamanhos individuais, subtrai as sobreposições duplas, soma de volta as triplas — alternando sinais até que cada elemento seja contado exatamente uma vez.
Dois conjuntos #
O diagrama de Venn abaixo ajuda a visualizar por que a interseção é contada duas vezes:
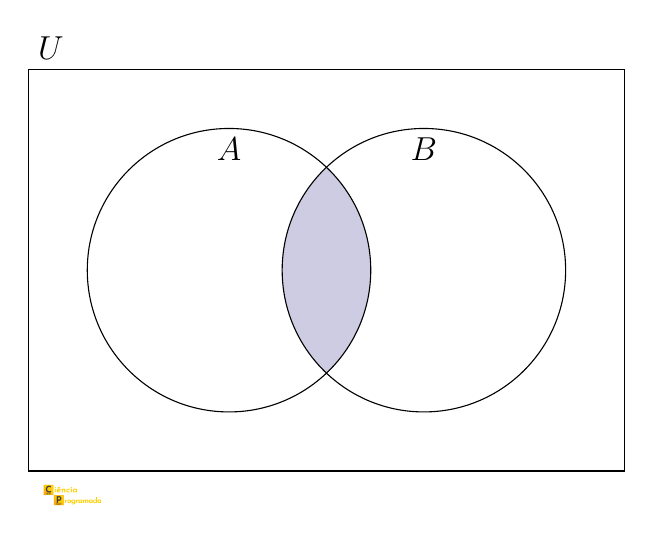
Por que subtrair a interseção? Ao somar \(n(A)\) e \(n(B)\), cada elemento que pertence a ambos os conjuntos é contado duas vezes — uma quando contamos \(A\) e outra quando contamos \(B\). Subtrair \(n(A \cap B)\) restaura a contagem correta.
A fórmula tem uma derivação elegante. Podemos decompor a união em três regiões disjuntas:
$$A \cup B = (A - B) \cup (A \cap B) \cup (B - A)$$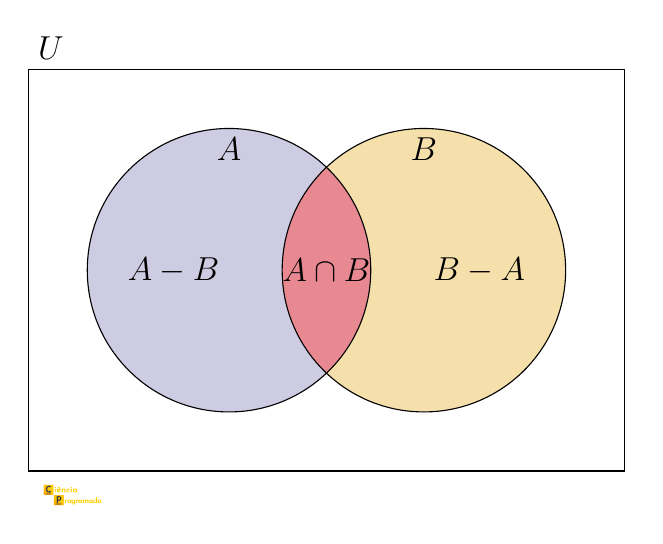
Pelo princípio aditivo:
$$n(A \cup B) = n(A - B) + n(A \cap B) + n(B - A)$$Mas também:
$$n(A - B) = n(A) - n(A \cap B) \qquad \text{e} \qquad n(B - A) = n(B) - n(A \cap B)$$Substituindo:
$$n(A \cup B) = \bigl[n(A) - n(A \cap B)\bigr] + n(A \cap B) + \bigl[n(B) - n(A \cap B)\bigr] = n(A) + n(B) - n(A \cap B)$$
Aplicação em analytics: usuários únicos (MAU)
Equipes de produto monitoram o MAU (Monthly Active Users) — o número de usuários únicos que acessaram a plataforma em determinado mês. Suponha que um serviço de streaming registre:
- \(n(Web) = 50,000\) acessos pelo navegador
- \(n(App) = 40,000\) acessos pelo aplicativo móvel
Somar diretamente os dois valores daria 90 000, mas muitos usuários acessam pelos dois canais. Se \(n(Web \cap App) = 15,000\), o total real de usuários únicos é:
$$n(Web \cup App) = 50\,000 + 40\,000 - 15\,000 = \mathbf{75\,000}$$O Princípio da Inclusão-Exclusão corrige a dupla contagem que infla a métrica — exatamente o mesmo papel que exerce na teoria.
Aplicação em engenharia de dados: deduplicação em pipelines ETL (Extract, Transform, Load)
Ao integrar dados de múltiplas fontes — CRM (Customer Relationship Management), plataforma de e-commerce e sistema de suporte — uma empresa precisa saber quantos clientes únicos possui no total. Cada fonte mantém sua própria lista e os mesmos clientes podem aparecer em mais de um sistema.
Se \(n(CRM) = 12,000\), \(n(Loja) = 8,000\) e \(n(CRM \cap Loja) = 3,000\), o número real de clientes distintos é:
$$n(CRM \cup Loja) = 12\,000 + 8\,000 - 3\,000 = \mathbf{17\,000}$$Em pipelines ETL, o PIE permite obter o total de registros únicos diretamente a partir de contagens parciais — sem precisar construir nem varrer a lista unificada completa.
Três conjuntos #
A lógica é a mesma: somamos os tamanhos individuais, subtraímos as sobreposições duplas (que foram contadas duas vezes) e adicionamos de volta a sobreposição tripla (que foi subtraída uma vez a mais do que deveria). A figura a seguir identifica cada uma dessas regiões no diagrama de Venn:
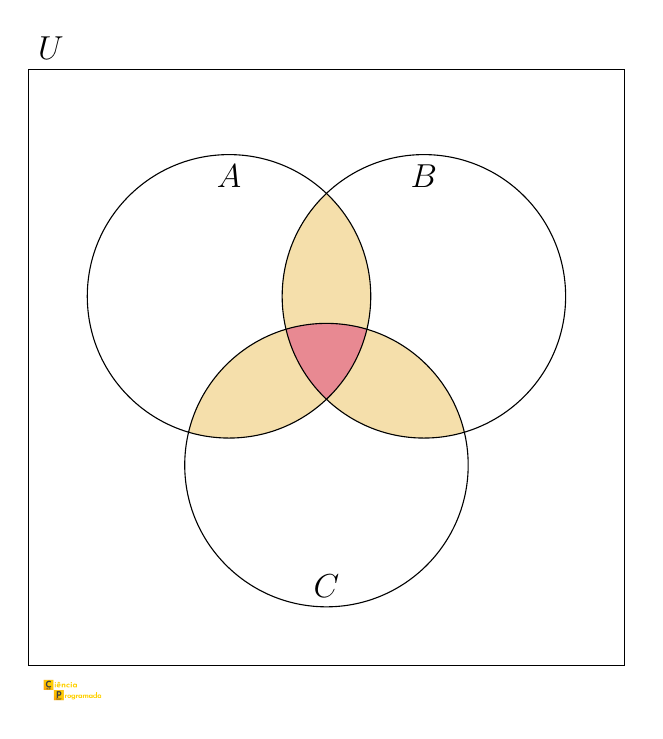
Uma derivação direta: aplique o caso de dois conjuntos a \((A \cup B) \cup C\), usando \(n(A \cup B)\) já desenvolvido e a identidade \((A \cup B) \cap C = (A \cap C) \cup (B \cap C)\).
Aplicação em QA (Quality Assurance): bugs únicos detectados por três suítes de teste
Uma equipe de qualidade mantém três suítes independentes — testes unitários (\(U\)), de integração (\(I\)) e de ponta a ponta (\(E\)) — e quer saber quantos bugs distintos foram encontrados no total, sem contar duas vezes os bugs detectados por mais de uma suíte.
Após uma rodada de testes:
- \(n(U) = 45\), \(n(I) = 38\), \(n(E) = 27\)
- \(n(U \cap I) = 12\), \(n(U \cap E) = 8\), \(n(I \cap E) = 10\)
- \(n(U \cap I \cap E) = 3\)
Somar os totais individuais daria 110 — 27 a mais do que o real, exatamente a quantidade de bugs contados em duplicata (ou triplicata) sem a correção do PIE.
Quatro conjuntos #
A fórmula para quatro conjuntos segue o mesmo padrão alternando sinais:
$$ \begin{aligned} n(A_1 \cup A_2 \cup A_3 \cup A_4) ={}& n(A_1)+n(A_2)+n(A_3)+n(A_4) \\ &- n(A_1 \cap A_2)-n(A_1 \cap A_3)-n(A_1 \cap A_4) \\ &- n(A_2 \cap A_3)-n(A_2 \cap A_4)-n(A_3 \cap A_4) \\ &+ n(A_1 \cap A_2 \cap A_3)+n(A_1 \cap A_2 \cap A_4) \\ &+ n(A_1 \cap A_3 \cap A_4)+n(A_2 \cap A_3 \cap A_4) \\ &- n(A_1 \cap A_2 \cap A_3 \cap A_4) \end{aligned} $$Fórmula geral #
Para \(k\) conjuntos, a fórmula geral do Princípio da Inclusão-Exclusão é:
$$n\!\left(\bigcup_{i=1}^{k} A_i\right) = \sum_{i} n(A_i) - \sum_{i < j} n(A_i \cap A_j) + \sum_{i < j < l} n(A_i \cap A_j \cap A_l) - \cdots + (-1)^{k+1}\, n(A_1 \cap \cdots \cap A_k)$$O padrão é claro: somamos os tamanhos individuais, subtraímos as interseções duplas, somamos as triplas, e assim por diante — alternando sinais.
Aplicação em ciência de dados: Similaridade de Jaccard
Uma métrica amplamente usada para comparar conjuntos — em sistemas de recomendação, detecção de plágio e agrupamento de documentos — é a Similaridade de Jaccard:
$$J(A, B) = \frac{n(A \cap B)}{n(A \cup B)}$$O denominador raramente é calculado materializando o conjunto união. O Princípio da Inclusão-Exclusão permite obtê-lo diretamente de contagens:
$$n(A \cup B) = n(A) + n(B) - n(A \cap B)$$Assim, a similaridade pode ser computada a partir de três inteiros — sem construir o conjunto \(A \cup B\) explicitamente.
Exemplo: dois usuários de uma plataforma de streaming. O usuário X assistiu aos filmes \(\{\text{A, B, C, D}\}\) e o usuário Y assistiu a \(\{\text{C, D, E, F}\}\). Os filmes em comum são \(\{\text{C, D}\}\), logo \(n(X \cap Y) = 2\). Pelo PIE:
$$n(X \cup Y) = 4 + 4 - 2 = 6 \implies J(X, Y) = \frac{2}{6} \approx 0{,}33$$Quanto mais próximo de 1, mais parecidos os gostos — sem precisar listar todos os filmes assistidos por pelo menos um dos dois.
Em larga escala, técnicas como MinHash estimam \(J(A, B)\) diretamente, sem passar pelo PIE — aproveitando que a probabilidade de dois conjuntos compartilharem o mesmo hash mínimo é igual à própria similaridade de Jaccard.
Aplicação em bancos de dados: estimativa de cardinalidade em query planners
Otimizadores de consulta SQL (como os do PostgreSQL e do MySQL) precisam
estimar, antes de executar, quantas linhas cada operação retornará —
essa estimativa determina a ordem dos JOINs e o índice a usar. Quando
uma cláusula WHERE combina dois predicados com OR, o otimizador precisa
estimar \(n(A \cup B)\), onde \(A\) e \(B\) são os conjuntos de linhas
que satisfazem cada predicado individualmente.
Sem o Princípio da Inclusão-Exclusão, o otimizador superestimaria o resultado ao somar as seletividades. Com ele, usa:
$$n(A \cup B) \approx n(A) + n(B) - n(A \cap B)$$As estimativas de \(n(A)\) e \(n(B)\) vêm dos histogramas de coluna
mantidos pelo banco. Para \(n(A \cap B)\), o comportamento padrão é assumir
independência entre os predicados: se 30% das linhas satisfazem o
predicado \(A\) e 20% satisfazem \(B\), o otimizador supõe que os dois
critérios não têm relação entre si e estima que 6% das linhas satisfazem
ambos — como se fossem eventos independentes (estudados em probabilidade).
Estatísticas estendidas (como CREATE STATISTICS no PostgreSQL) refinam essa
estimativa quando os atributos são correlacionados, mas exigem configuração
explícita.
O PIE aparece, portanto, em todo plano de execução que envolva predicados
com OR — invisível ao desenvolvedor, mas presente na aritmética do
otimizador.
Tabela-Resumo #
As fórmulas desenvolvidas ao longo do artigo, reunidas para consulta rápida:
| Situação | Fórmula |
|---|---|
| Disjuntos (\(A \cap B = \emptyset\)) | \(n(A \cup B) = n(A) + n(B)\) |
| Dois conjuntos | \(n(A \cup B) = n(A) + n(B) - n(A \cap B)\) |
| Três conjuntos | \(n(A \cup B \cup C) = \sum n - \sum n(\cap_2) + n(\cap_3)\) |
| Complemento | \(n(U - A) = n(U) - n(A)\) |
| Diferença | \(n(A - B) = n(A) - n(A \cap B)\) |
Na linha dos três conjuntos, \(\sum n\) abrevia a soma dos três tamanhos individuais, \(\sum n(\cap_2)\) é a soma das três interseções duplas (\(n(A \cap B) + n(A \cap C) + n(B \cap C)\)) e \(n(\cap_3)\) é a interseção tripla \(n(A \cap B \cap C)\). As linhas de complemento e diferença seguem diretamente do princípio aditivo: basta decompor o conjunto maior em duas partes disjuntas e isolar o termo desejado.
Exercícios #
Exercício 1 — Divisibilidade em \(\{1, \ldots, 100\}\)
Quantos números de 1 a 100 não são divisíveis por 2 nem por 5?
Seja \(C = \{1, \ldots, 100\}\), \(A\) = divisíveis por 2, \(B\) = divisíveis por 5.
- \(n(A) = 50\) (todo segundo número)
- \(n(B) = 20\) (todo quinto número)
- \(n(A \cap B) = 10\) (divisíveis por 10)
Os não divisíveis por 2 nem por 5:
$$n(C) - n(A \cup B) = 100 - 60 = \mathbf{40}$$
Exercício 2 — Demonstração
Sejam \(A\) e \(B\) dois subconjuntos de \(U\) com \(B \subseteq A\). Prove, usando o princípio aditivo, que \(n(A - B) = n(A) - n(B)\).
Demonstração: Como \(B \subseteq A\), temos \(A \cup B = A\). Podemos reescrever \(A\) como a união disjunta \(A = (A - B) \cup B\). Pelo princípio aditivo:
$$n(A) = n(A - B) + n(B)$$Portanto \(n(A - B) = n(A) - n(B)\). \(\blacksquare\)
Exercício 3 — Múltiplos de 3 ou 7 até 100
Quantos inteiros de 1 a 100 são divisíveis por 3 ou por 7?
Solução: Seja \(A\) = múltiplos de 3, \(B\) = múltiplos de 7, em \(\{1,\ldots,100\}\).
- \(n(A) = \lfloor 100/3 \rfloor = 33\)
- \(n(B) = \lfloor 100/7 \rfloor = 14\)
- \(n(A \cap B)\) = múltiplos de \(\text{mmc}(3,7) = 21\): \(\{21, 42, 63, 84\}\), logo \(n(A \cap B) = 4\)
Exercício 4 — Múltiplos em \((1, 60)\)
Considere os inteiros de 2 a 59. Determine quantos são:
(i) divisíveis por 2 e por 3 (ii) divisíveis por 2 ou por 3 (iii) não divisíveis nem por 2 nem por 3
(iv) ímpares divisíveis por 3, ou divisíveis por 2 (v) divisíveis por 2, 3 ou 5
Soluções: Sejam \(A\) = pares, \(B\) = múltiplos de 3, todos em \((1,60)\) (excluindo os extremos):
\(n(A) = 29\), \(n(B) = 19\), \(n(A \cap B) = 9\) (múltiplos de 6).
(i) \(n(A \cap B) = \mathbf{9}\)
(ii) \(n(A \cup B) = 29 + 19 - 9 = \mathbf{39}\)
(iii) Total = 58 números. Não em \(A \cup B\): \(58 - 39 = \mathbf{19}\)
(iv) \(D\) = ímpares múltiplos de 3 = \(\{3,9,15,21,27,33,39,45,51,57\}\), \(n(D) = 10\). Como \(A \cap D = \emptyset\): \(n(A \cup D) = 29 + 10 = \mathbf{39}\)
(v) \(E\) = múltiplos de 5 em \((1,60)\) = \(\{5,10,\ldots,55\}\), \(n(E) = 11\). \(n(A \cap E) = 5\), \(n(B \cap E) = 3\), \(n(A \cap B \cap E) = 1\).
$$n(A \cup B \cup E) = 29+19+11-9-5-3+1 = \mathbf{43}$$
Exercício 5 — Pesquisa de mercado
Foram consultadas 200 pessoas sobre preços de televisores: 40% perguntaram pela marca A, 35% pela marca B, 10% por ambas e 35% não perguntaram por nenhuma das duas marcas. Determine:
(i) quantas perguntaram por A ou B
(ii) quantas perguntaram por A e não por B
Soluções: Em valores absolutos: \(n(A) = 80\), \(n(B) = 70\), \(n(A \cap B) = 20\).
(i) \(n(A \cup B) = 80 + 70 - 20 = \mathbf{130}\) pessoas
(ii) \(n(A - B) = n(A) - n(A \cap B) = 80 - 20 = \mathbf{60}\) pessoas
Crivo de Eratóstenes #
Os exercícios 1, 3 e o item (v) do 4 seguem o mesmo esquema: definir um conjunto por divisibilidade, calcular sua cardinalidade com \(\lfloor n/k \rfloor\), usar o PIE para reunir múltiplos de diferentes primos sem dupla contagem e, quando necessário, tomar o complemento para contar os elementos que não satisfazem nenhuma das condições. Esse padrão — contar pelo complemento após aplicar o PIE — é recorrente em combinatória.
Esses exercícios de divisibilidade aplicam exatamente o mesmo raciocínio do Crivo de Eratóstenes (Sieve of Eratosthenes), o algoritmo mais antigo conhecido para encontrar todos os números primos até um limite \(n\), proposto pelo matemático grego Eratóstenes de Cirene no século III a.C.
Um número primo é um número natural que possui exatamente dois divisores naturais distintos: o número 1 e ele mesmo.
Os primeiros primos são 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, …
Como funciona #
Dado um inteiro \(n > 1\), o método de Eratóstenes:
- Crie uma lista de inteiros consecutivos de 2 a \(n\).
- Seja \(p = 2\), o menor primo.
- Marque como compostos todos os múltiplos de \(p\) a partir de \(2p\): \(2p,\ 3p,\ 4p,\ \ldots\) — o próprio \(p\) não é marcado.
- Encontre o menor número da lista maior que \(p\) ainda não marcado. Se não houver, pare. Caso contrário, \(p\) assume esse novo valor e volte ao passo 3.
- Ao terminar, os números não marcados são todos os primos até \(n\).
A ideia central: todo valor assumido por \(p\) é necessariamente primo — se fosse composto, já teria sido marcado como múltiplo de algum primo menor. Note que, neste algoritmo básico, alguns números podem ser marcados mais de uma vez: 15, por exemplo, é marcado tanto ao processar \(p = 3\) quanto ao processar \(p = 5\).
Otimização: no passo 3, é suficiente começar em \(p^2\) em vez de \(2p\), pois todo múltiplo \(k \cdot p\) com \(k < p\) tem um fator primo \(q \leq k < p\) pelo qual já foi marcado em uma etapa anterior. Com isso, também basta executar o passo 3 enquanto \(p^2 \leq n\): ao atingir um \(p\) com \(p^2 > n\), todos os números ainda não marcados são necessariamente primos.
Por exemplo, ao processar \(p = 5\), os múltiplos anteriores a \(p^2 = 25\) já foram marcados: \(10 = 2 \cdot 5\) foi marcado quando \(p = 2\); \(15 = 3 \cdot 5\), quando \(p = 3\); \(20 = 4 \cdot 5 = 2^2 \cdot 5\), novamente quando \(p = 2\). O primeiro múltiplo de 5 que ainda pode estar sem marca é \(25 = 5^2\) — daí o início em \(p^2\).
A animação abaixo ilustra o algoritmo completo com a otimização aplicada, para todos os primos abaixo de 121:

Exemplo para \(n = 30\) — em negrito os primos, riscados os compostos:
| 2 | 3 | 5 | 7 | 11 | |||||
| 13 | 17 | 19 | |||||||
| 23 | 29 |
Com \(p = 2\): marcam-se 4, 6, 8, …, 30. Com \(p = 3\): marcam-se 9, 15, 21, 27 (os pares já estavam marcados). Com \(p = 5\): marca-se 25. O próximo primo seria \(p = 7\), mas \(7^2 = 49 > 30\): os únicos múltiplos de 7 no intervalo — 14, 21 e 28 — já estão marcados por primos menores (2 e 3). Todos os números ainda não marcados são primos. Restam dez — os primos de 2 a 29.
Algoritmo #
O pseudocódigo abaixo incorpora diretamente a otimização de \(p^2\):
Entrada: inteiro n > 1
Saída: todos os primos de 2 a n
A ← vetor[2..n] inicializado com True
Para i de 2 até √n:
Se A[i] for True:
Para j de i² até n com passo i:
A[j] ← False
Retorne todos i com A[i] = TrueO fluxograma abaixo representa o mesmo algoritmo de forma visual:
flowchart TD
A([Início]) --> B["A ← vetor[2..n] = True
i ← 2"]
B --> C{"i ≤ √n ?"}
C -- Não --> G[/"Retorne todos i
com A[i] = True"/]
G --> H([Fim])
C -- Sim --> D{"A[i] = True ?"}
D -- Não --> F["i ← i + 1"]
F --> C
D -- Sim --> E["j ← i²"]
E --> I{"j ≤ n ?"}
I -- Não --> F
I -- Sim --> J["A[j] ← False"]
J --> K["j ← j + i"]
K --> I
No pseudocódigo, a mesma otimização aparece sob dois ângulos: o laço interno começa em \(i^2\) porque múltiplos anteriores já foram marcados; o laço externo para em \(\sqrt{n}\) porque, quando \(i > \sqrt{n}\), temos \(i^2 > n\) — não existe nenhum múltiplo de \(i\) a partir de \(i^2\) dentro do intervalo. As duas condições são equivalentes.
Complexidade de tempo: \(O(n \log \log n)\). A intuição: para cada primo \(p \leq n\), o laço interno executa cerca de \(n/p\) passos. O custo total é proporcional a \(n \sum_{p \leq n} 1/p\), e pelo teorema de Mertens essa soma cresce como \(\log \log n\) — muito mais lentamente que \(\log n\) (série harmônica completa). Na prática, para \(n = 10^9\), \(\log \log n \approx 4{,}4\): o algoritmo é quase linear.
Complexidade de espaço: o pseudocódigo acima aloca um vetor de \(n\) posições, logo \(O(n)\) — inviável para \(n = 10^9\). O Crivo Segmentado (Segmented Sieve) é uma variante que reduz o espaço para \(O(\sqrt{n})\) sem aumentar a complexidade de tempo. A ideia em duas fases: primeiro, roda o crivo clássico até \(\sqrt{n}\) para obter todos os primos pequenos — esse vetor cabe em \(O(\sqrt{n})\); depois, divide \([2, n]\) em blocos de tamanho \(\approx \sqrt{n}\) (dimensionados para caber na memória cache do processador) e processa um bloco por vez, marcando os múltiplos dos primos pequenos que caem naquele intervalo. O pseudocódigo resultante é mais longo que o acima, mas o princípio é o mesmo.
Propriedade fundamental: o crivo usa apenas adições — avança contando em incrementos de \(p\) —, sem divisões nem testes de divisibilidade. É isso que o distingue da divisão por tentativa (trial division), que testa cada candidato individualmente, e é a base de sua eficiência.
A conexão com o PIE #
Por que o crivo funciona matematicamente? Todo número composto \(m \leq n\) tem pelo menos um fator primo \(p \leq \sqrt{m} \leq \sqrt{n}\) — logo todo composto cai em algum \(A_p\) e é eliminado. O que sobra são os primos.
Voltando ao exemplo com \(n = 30\): \(21 = 3 \times 7\) é composto e \(\sqrt{21} \approx 4{,}6\), logo tem um fator primo \(\leq 4{,}6\) — de fato, 3 — e foi eliminado quando \(p = 3\). Já \(25 = 5^2\) tem \(\sqrt{25} = 5\), com fator primo \(5 \leq 5\), eliminado quando \(p = 5\). Nenhum composto escapa: sempre existe um fator primo pequeno o suficiente para tê-lo marcado antes de o laço externo terminar.
Eliminar múltiplos de um primo \(p\) equivale a definir:
$$A_p = \{k \in \{1, \ldots, n\} : k \text{ é múltiplo de } p\}$$Em palavras: \(A_p\) é o conjunto de todos os inteiros de 1 a \(n\) que o crivo marcaria ao processar o primo \(p\). Por exemplo, para \(p = 3\) e \(n = 30\), temos \(A_3 = \{3, 6, 9, 12, \ldots, 30\}\). Cada passo do algoritmo nada mais faz do que construir esse conjunto e riscar seus elementos.
Os sobreviventes do crivo são os inteiros de 1 a \(n\) que não pertencem a nenhum \(A_p\) — ou seja, o complemento da união de todos esses conjuntos. Chamando de \(p_1, \ldots, p_r\) os primos até \(\sqrt{n}\), a contagem dos sobreviventes é:
$$n - n(A_{p_1} \cup \cdots \cup A_{p_r})$$(O número 1 também sobrevive, por não ser divisível por nenhum primo; os próprios \(p_1, \ldots, p_r\) são excluídos, pois cada \(p_i\) pertence ao seu próprio \(A_{p_i}\). O crivo parte de 2, o que resolve ambos na prática.)
Para calcular \(n(A_{p_1} \cup \cdots \cup A_{p_r})\), aplicamos o PIE. Isso exige conhecer as cardinalidades individuais e das interseções. A chave é que a interseção de dois conjuntos de múltiplos é ela mesma um conjunto de múltiplos: \(A_p \cap A_q\) contém exatamente os inteiros divisíveis por \(p\) e por \(q\) — isto é, os múltiplos do produto \(pq\) (que é o mmc de dois primos distintos). Portanto:
- A cardinalidade de \(A_p\) é o número de múltiplos de \(p\) até \(n\), dado pela parte inteira \(\lfloor n/p \rfloor\).
- A cardinalidade da interseção \(A_p \cap A_q\) é o número de múltiplos de \(pq\) até \(n\), dado por \(\lfloor n/(pq) \rfloor\).
Você calculou exatamente isso no item (v) do Exercício 4: com \(A\) = pares, \(B\) = múltiplos de 3 e \(E\) = múltiplos de 5 no intervalo \((1, 60)\), você aplicou o PIE a \(A_2 \cup A_3 \cup A_5\) e obteve 43. O exercício parou aí — mas o crivo dá um passo a mais: toma o complemento, \(58 - 43 = 15\), para contar os sobreviventes (os números de 2 a 59 não divisíveis por 2, 3 nem 5, que incluem todos os primos maiores que 5 nesse intervalo). O Crivo de Eratóstenes é esse raciocínio generalizado para qualquer \(n\) e qualquer conjunto de primos.
O Crivo de Eratóstenes é um algoritmo: marca múltiplos iterativamente e conta o que sobra. O que fizemos nesta seção foi diferente — expressamos o mesmo resultado como uma fórmula fechada via PIE, calculando diretamente \(n - n(A_{p_1} \cup \cdots \cup A_{p_r})\) sem simular o processo passo a passo. Essa formalização matemática é historicamente conhecida como o Crivo de Legendre (ou Crivo de Legendre–Eratóstenes), nomeado em homenagem a Adrien-Marie Legendre, que no século XIX tornou explícita a estrutura do PIE por trás do crivo. A fórmula central do método é chamada de Identidade de Legendre, e ela generaliza a expressão acima usando a função de Möbius \(\mu(d)\). Essa função codifica exatamente o padrão de sinais alternados do PIE: para um número \(d\) que é produto de \(k\) primos distintos, \(\mu(d) = (-1)^k\); se \(d\) contém algum fator ao quadrado, \(\mu(d) = 0\). Com isso, toda a expansão do PIE — somar os individuais, subtrair os pares, somar as triplas… — se condensa numa única soma:
$$n - \sum_{d \mid P} \mu(d) \left\lfloor \frac{n}{d} \right\rfloor$$onde \(P = p_1 \cdot p_2 \cdots p_r\) é o produto dos primos até \(\sqrt{n}\). É a mesma aritmética do PIE, reescrita de forma compacta.
Próximos passos #
Com cardinalidade e o Princípio da Inclusão-Exclusão, fechamos o bloco teórico fundamental desta etapa da série: definir, representar, operar e contar conjuntos sem dupla contagem.
No próximo artigo da série, a mesma linguagem aparece em código:
veremos como pertinência, inclusão, união, interseção e cardinalidade se
traduzem diretamente em Python com o uso de set e frozenset, conectando a
teoria à prática.
Nos vemos lá!


