
No artigo anterior — Hierarquia de Memória — vimos que a DRAM é lenta demais para o processador e que a SRAM, apesar de rápida, é cara demais para grandes volumes. Terminamos com os princípios de localidade temporal e espacial: a observação empírica de que programas reais tendem a reusar os mesmos dados e a acessar endereços vizinhos. São exatamente esses princípios que tornam a memória cache viável — e é o que vamos explorar agora.
Neste artigo você vai entender:
- o gargalo de velocidade entre CPU e DRAM e por que ele cresce com o tempo;
- como os princípios de localidade se traduzem em hit e miss;
- os três tipos de mapeamento que definem onde um bloco da MP pode ir na cache;
- os algoritmos que decidem qual bloco substituir quando a cache está cheia;
- as políticas de escrita e como elas mantêm consistência entre cache e MP;
- a organização física da memória em chips: 1D versus 2D.
O problema de velocidade UCP/MP #
A DRAM transfere dados para a CPU em velocidade inferior àquela com que o processador consegue consumi-los. Quando isso acontece, a CPU precisa esperar, inserindo wait states (ciclos de espera) e ficando ociosa por parte do tempo.
Historicamente, o desempenho dos processadores evoluiu mais rápido do que a latência e a largura de banda da memória principal. Esse descompasso foi uma das principais razões para o surgimento da memória cache.
Em tese, uma solução simples seria construir toda a memória principal com SRAM, que é muito mais rápida. Na prática, isso é inviável: a SRAM ocupa mais área no chip e custa muito mais por bit armazenado. A solução de engenharia foi colocar uma memória pequena e muito rápida entre a CPU e a DRAM: a cache.
Por que a cache funciona?
A cache só é eficiente porque programas reais exibem localidade de acesso. Sem esse comportamento empiricamente observado, a cache não traria ganho de desempenho.
Princípios de localidade #
A eficiência da cache não é um acidente de projeto — ela depende de um comportamento observável nos programas reais chamado localidade de acesso. Dois princípios complementares descrevem esse comportamento:
| Princípio | Definição | Exemplo prático |
|---|---|---|
| Temporal | Se o programa acessa a palavra \(X\), há grande probabilidade de acessar \(X\) novamente em breve | Variável de controle em um laço for |
| Espacial | Se o programa acessa a palavra \(X\), há grande probabilidade de acessar palavras próximas em seguida | Instruções sequenciais; elementos consecutivos de um array |
A cache explora ambos: ao ocorrer um miss, ela carrega um bloco inteiro de células contíguas (localidade espacial) e mantém esse bloco nos seus slots pelo máximo de tempo possível (localidade temporal). Para a maioria dos programas, isso significa que a grande maioria dos acessos subsequentes resulta em hit, sem necessidade de busca na DRAM. Mas como exatamente a CPU decide se o dado está na cache ou se precisa “descer” até a memória principal?
Funcionamento da cache #
A regra da arquitetura de computadores é: a CPU sempre tenta buscar instruções e dados na cache primeiro. A cada acesso, o hardware verifica se o bloco desejado já está presente nela:
graph TD
A["CPU solicita instrução ou dado"]
B{"Bloco presente
na cache?"}
H["HIT — Acerto
Dado transferido cache→CPU
em alta velocidade"]
M["MISS — Falta
Bloco completo transferido MP→cache
depois palavra→CPU"]
F["Dado entregue à CPU"]
A --> B
B -->|"Sim"| H --> F
B -->|"Não"| M --> F
| Situação | O que acontece | Granularidade da transferência |
|---|---|---|
| Hit (acerto) | Dado encontrado na cache | Palavra cache → CPU |
| Miss (falta) | Dado não encontrado | Bloco MP → cache; depois palavra → CPU |
A transferência em blocos no caso de miss explora a localidade espacial: se uma palavra foi necessária agora, há boa chance de palavras vizinhas também serem acessadas em seguida.
Tipos e níveis de cache #
Uma distinção útil é esta:
- quando falamos em memória cache neste artigo, o foco principal é a cache do processador, construída para reduzir o custo de acesso à memória principal;
- quando falamos em aceleração de acesso a disco, em sistemas atuais é comum encontrar o tema sob nomes como cache de sistema de arquivos ou page cache em RAM, e não necessariamente como “cache de disco” no sentido clássico.
Mas a ideia geral é sempre a mesma: usar uma camada mais rápida para amortecer o custo de acesso a uma camada mais lenta.
| Tipo | Relação acelerada | Implementação típica |
|---|---|---|
| Cache de CPU | CPU ↔ Memória Principal | SRAM |
| Cache de sistema de arquivos | RAM ↔ armazenamento secundário | DRAM |
| Nível | Localização típica | Velocidade | Capacidade típica |
|---|---|---|---|
| L1 | Interna ao núcleo do processador | Máxima | Dezenas de KB |
| L2 | Interna ao processador | Muito alta | Centenas de KB a poucos MB |
| L3 | Interna ao processador, geralmente compartilhada | Alta | Vários MB |
Cache dividida: em muitas arquiteturas, instruções e dados ficam em caches separadas, o que reduz conflitos e melhora o paralelismo interno.
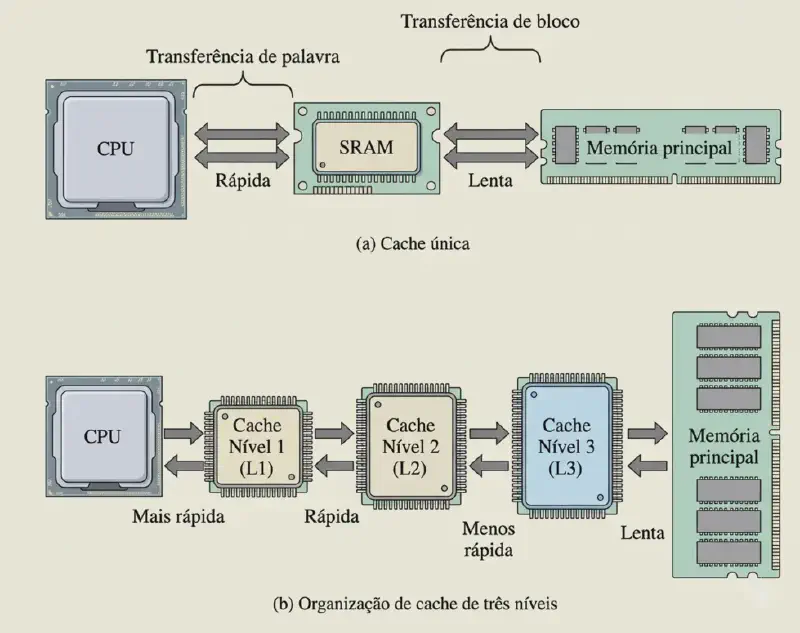
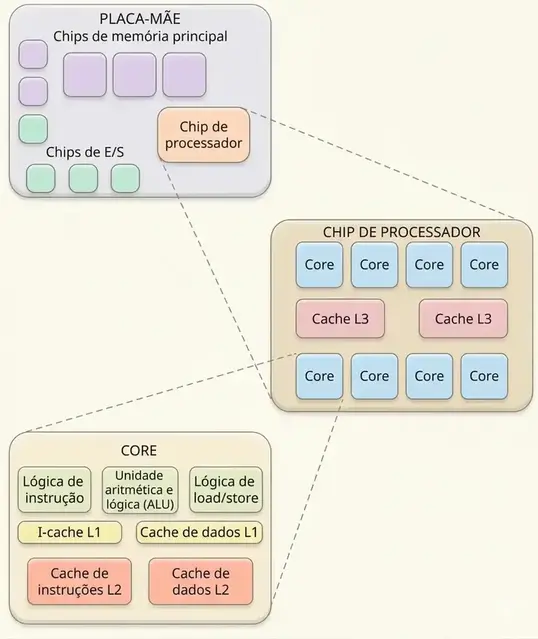
Evolução histórica dos níveis de cache
Em arquiteturas mais antigas, era comum que apenas a cache L1 ficasse dentro do processador, enquanto a L2 podia ficar fora dele, por exemplo na placa-mãe ou em um chip separado. Em processadores atuais, o mais comum é que L1, L2 e L3 estejam integradas ao próprio processador. Em muitos casos, L1 e L2 são privadas de cada core (núcleo), enquanto a L3 é compartilhada. As figuras abaixo ilustram essa evolução:
Os quatro elementos de projeto da cache #
Projetar uma memória cache não é apenas colocar um chip rápido perto da CPU. Os engenheiros de hardware precisam equilibrar custo, complexidade e desempenho. Esse equilíbrio orbita em torno de quatro elementos fundamentais:
| # | Elemento | Questão envolvida |
|---|---|---|
| 1 | Tamanho | Qual a capacidade total? (impacta custo, taxa de acerto e tempo de acesso) |
| 2 | Função de mapeamento | Como um bloco da MP é associado a uma linha da cache? |
| 3 | Algoritmo de substituição | Qual bloco remover quando ocorre um miss e não há linha livre? |
| 4 | Política de escrita | Como manter consistência entre cache e MP nas operações de escrita? |
Terminologia essencial:
- Bloco: unidade de transferência entre MP e cache; contém \(K\) células contíguas
- Linha: espaço na cache que acomoda um bloco
- \(B\) = número total de blocos na MP
- \(Q\) = número de linhas na cache, onde \(Q \ll B\)
Funções de mapeamento #
Mapeamento direto #
Cada bloco da MP tem uma única linha de cache possível na cache, determinada por:
$$\text{linha na cache} = \text{número do bloco} \bmod Q$$A figura abaixo ilustra o mapeamento direto, onde blocos da MP são mapeados para linhas específicas da cache. Note que blocos diferentes podem competir pela mesma linha, o que pode levar a conflitos frequentes.
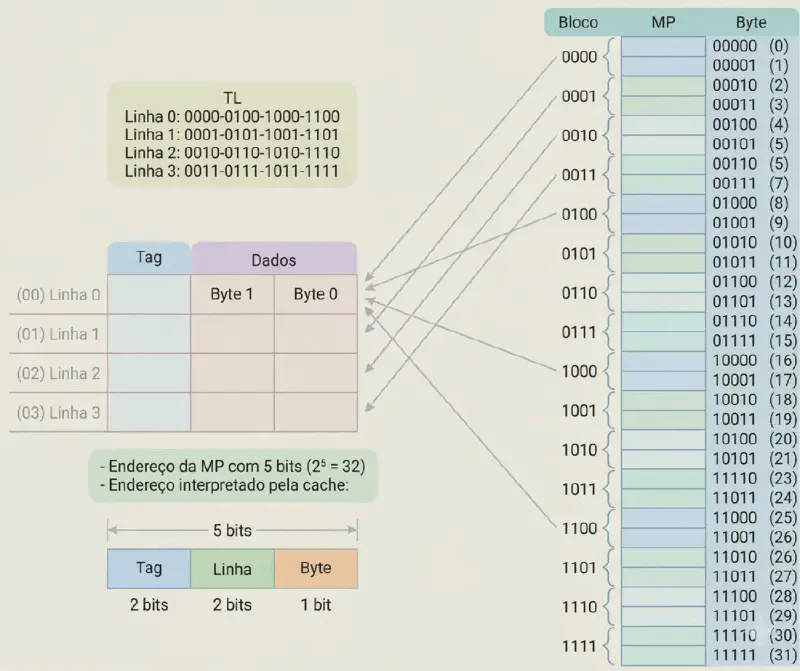
Divisão do endereço de \(E\) bits:
| Campo | Nº de bits | Função |
|---|---|---|
| Tag | \(E - \log_2 Q - \log_2 K\) | Identifica qual dos \(B/Q\) blocos está nessa linha |
| Nº da linha | \(\log_2 Q\) | Seleciona a linha da cache |
| Palavra no bloco | \(\log_2 K\) | Seleciona a célula/palavra dentro do bloco |
Exemplo numérico — Mapeamento direto
- MP = 4Gbytes endereçáveis → \(E = 32\) bits
- Cache: \(Q = 1024\) linhas, \(K = 64\) bytes/bloco
- Bits de linha: \(\log_2 1024 = 10\)
- Bits de palavra: \(\log_2 64 = 6\)
- Bits de tag: \(32 - 10 - 6 = 16\)
- Total de blocos: \(B = 4G / 64 = 64M\) → 65.536 blocos mapeados para cada linha!
| Aspecto | Mapeamento direto |
|---|---|
| ✅ Vantagem | Simples e barato de implementar |
| ❌ Desvantagem | Conflito de blocos: dois blocos na mesma linha se substituem mutuamente, mesmo que outras linhas estejam livres |
Para resolver esse problema de “esmagamento” constante do mapeamento direto, os engenheiros propuseram o extremo oposto: dar liberdade total ao bloco.
Mapeamento associativo (fully associative) #
Um bloco pode ser alocado em qualquer linha da cache.
A figura abaixo mostra o mapeamento associativo, onde blocos da MP podem ser armazenados em qualquer linha da cache, eliminando completamente os conflitos de blocos. No entanto, isso exige uma lógica de busca mais complexa para localizar um bloco específico.
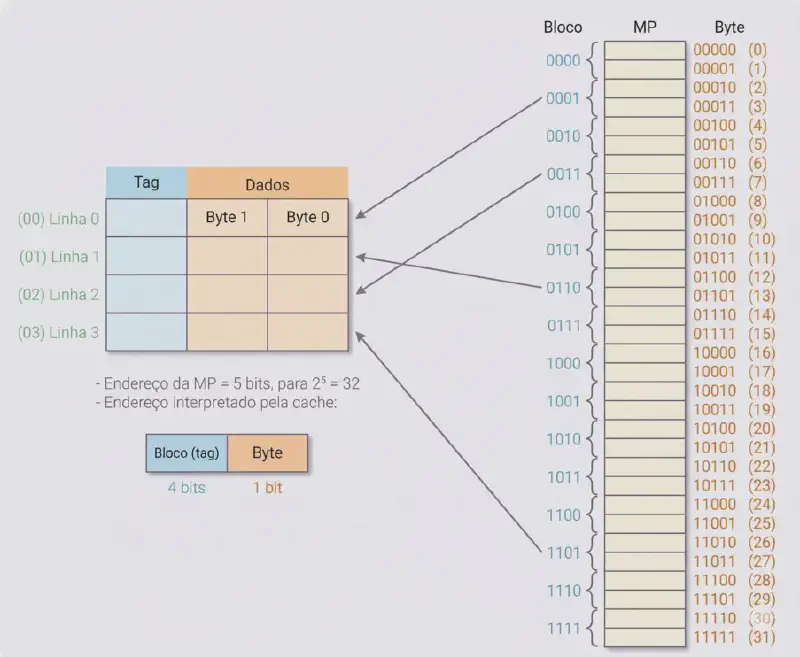
Divisão do endereço:
| Campo | Nº de bits | Função |
|---|---|---|
| Tag | \(E - \log_2 K\) | Identifica o bloco (= número do bloco na MP) |
| Palavra no bloco | \(\log_2 K\) | Seleciona a palavra dentro do bloco |
Para localizar um bloco, o controlador compara a tag com todas as \(Q\) linhas simultaneamente (hardware paralelo).
| Aspecto | Mapeamento associativo |
|---|---|
| ✅ Vantagem | Elimina completamente conflitos de blocos |
| ❌ Desvantagem | Lógica de busca complexa e cara; impraticável para caches grandes |
Como a busca paralela em todas as linhas gera um hardware muito caro, a indústria precisou encontrar um meio-termo entre a rigidez do mapeamento direto e o alto custo do associativo.
Mapeamento associativo por conjuntos (set-associative) #
Compromisso entre os dois anteriores. A cache é dividida em \(C\) conjuntos (sets) de \(D\) linhas cada:
$$Q = C \times D \qquad\qquad \text{conjunto} = \text{número do bloco} \bmod C$$A figura abaixo ilustra o mapeamento associativo por conjuntos, onde a cache é dividida em conjuntos, e cada bloco da MP é mapeado para um conjunto específico, mas pode ocupar qualquer linha dentro desse conjunto. Isso reduz os conflitos de blocos em comparação com o mapeamento direto, enquanto mantém a complexidade de busca mais gerenciável do que o associativo total.
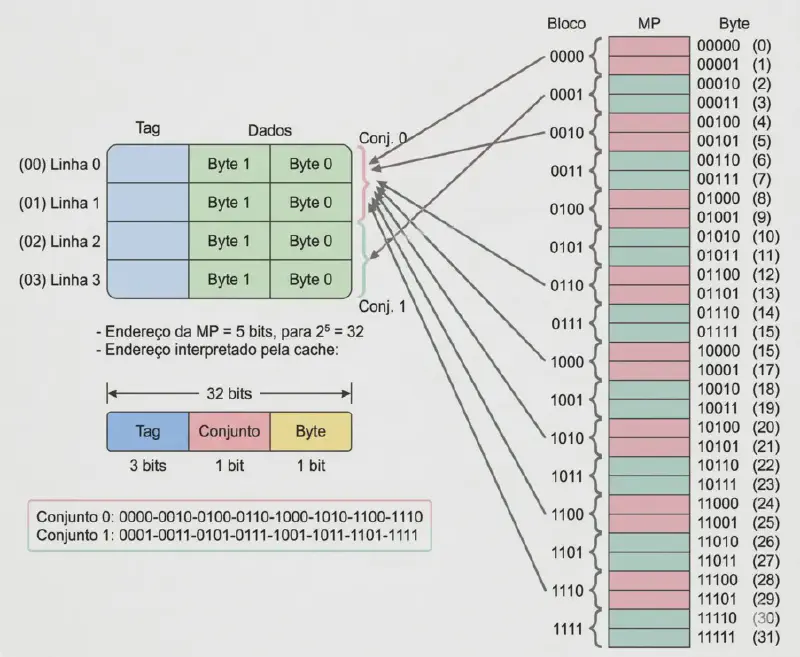
Divisão do endereço:
| Campo | Nº de bits | Função |
|---|---|---|
| Tag | \(E - \log_2 C - \log_2 K\) | Identifica o bloco dentro do conjunto |
| Nº do conjunto | \(\log_2 C\) | Seleciona o conjunto |
| Palavra no bloco | \(\log_2 K\) | Seleciona a palavra |
A tag é comparada apenas com as \(D\) linhas do conjunto — não com toda a cache.
graph LR
B0["MP: Bloco 0
(0 mod C = 0)"]
BC["MP: Bloco C
(C mod C = 0)"]
B1["MP: Bloco 1
(1 mod C = 1)"]
BC1["MP: Bloco C+1
(C+1 mod C = 1)"]
subgraph S0["Conjunto 0 — D linhas"]
L00["Linha 0"]
L01["Linha 1"]
end
subgraph S1["Conjunto 1 — D linhas"]
L10["Linha 0"]
L11["Linha 1"]
end
B0 --> L00
BC --> L01
B1 --> L10
BC1 --> L11
Comparativo das três técnicas #
| Técnica | Flexibilidade | Complexidade | Custo | Conflito de blocos |
|---|---|---|---|---|
| Direto | Baixa (1 linha fixa por bloco) | Baixa | Baixo | Frequente |
| Associativo | Total (qualquer linha) | Alta | Alto | Nenhum |
| Assoc. por conjuntos | Média (\(D\) linhas por conjunto) | Média | Médio | Reduzido |
Técnica mais usada nos processadores modernos
O mapeamento associativo por conjuntos com \(D = 2\), \(4\) ou \(8\) vias (ways) domina os projetos atuais. Equilibra o baixo custo do mapeamento direto com a flexibilidade do associativo total.
Vejamos como calcular os campos de endereço para cada técnica em um exemplo concreto:
Exemplo — Campos de endereço nos três tipos de mapeamento
Uma máquina pode endereçar 4 Gbytes de memória física com células de 2 bytes, organizada em blocos de 1 Kbyte. A cache comporta 2K linhas (um bloco por linha). Calcule os campos de endereço para os três tipos de mapeamento.
Dados: 4 Gbytes; célula = 2 bytes → \(N = 2\text{G} = 2^{31}\) células → \(E = 31\) bits. Bloco = 1 Kbyte = 512 células → \(B = 2^{31}/2^9 = > 2^{22} = 4\text{M}\) blocos. Cache: \(Q = 2\text{K} = 2^{11}\) linhas.
Mapeamento direto:
$$\underbrace{11}_{\text{tag}} \underbrace{11}_{\text{linha}} \underbrace{9}_{\text{palavra}} = 31\ \text{bits}$$- campo linha: \(Q = 2^{11}\) → 11 bits; campo palavra: \(2^9\) → 9 bits
- campo tag: \(B/Q = 2^{22}/2^{11} = 2^{11}\) → 11 bits
Mapeamento totalmente associativo:
$$\underbrace{22}_{\text{tag}} \underbrace{9}_{\text{palavra}}$$- campo tag: \(B = 2^{22}\) → 22 bits; campo palavra: 9 bits
Mapeamento associativo por conjuntos (\(D = 4\)):
- \(C = Q/D = 2^{11}/4 = 2^9\) conjuntos $$\underbrace{13}_{\text{tag}} \underbrace{9}_{\text{conjunto}} \underbrace{9}_{\text{palavra}} = 31\ \text{bits}$$
- campo conjunto: 9 bits; campo tag: \(B/C = 2^{22}/2^9 = 2^{13}\) → 13 bits; campo palavra: 9 bits
A interpretação dos campos fica mais clara quando analisamos o que acontece em hit e miss para um endereço específico:
Exemplo — Hit e miss para um endereço dado
Uma máquina com 32 Gbytes de memória física tem células de 4 bytes e uma cache
com 16 M blocos (1 bloco por linha, 8 células por bloco). Para o endereço 2
(binário: 0000...010), o que caracteriza hit e miss em cada tipo?
Dados: \(N = 8\text{G} = 2^{33}\) → \(E = 33\) bits. Bloco = 8 células → \(B = 2^{33}/2^3 = 2^{30}\) blocos. Cache: \(Q = 2^{24}\). Campo palavra: \(2^3\) → 3 bits.
Mapeamento direto: campo linha: 24 bits; tag: \(2^{30}/2^{24} =
> 2^6\) → 6 bits. Endereço 2: 000000 | 000...000 | 010.
- Hit: vai à linha dos 24 bits centrais, compara tag — se iguais, acesso direto.
- Miss: tags diferentes → bloco inteiro transferido da MP.
Totalmente associativo: campo tag: 30 bits.
- Hit: pesquisa em todas as linhas em paralelo; se alguma tag coincidir → acerto.
- Miss: nenhuma linha tem a tag → bloco transferido.
Associativo por conjuntos (\(D = 4\)): \(C = 2^{24}/4 = 2^{22}\); campo conjunto: 22 bits; tag: \(2^{30}/2^{22} = 2^8\) → 8 bits.
- Hit: localiza o conjunto pelos 22 bits centrais; compara tag nas 4 linhas.
- Miss: nenhuma das 4 linhas tem a tag → bloco transferido.
Algoritmos de substituição #
Quando ocorre um miss e não há linha livre disponível, o controlador precisa decidir qual bloco antigo será removido para dar lugar ao novo.
Essa decisão só existe nos casos em que há escolha possível, isto é, no mapeamento associativo e no mapeamento associativo por conjuntos. No mapeamento direto, o bloco novo sempre substitui o bloco que já ocupa a única linha compatível com ele.
| Algoritmo | Estratégia | Observação |
|---|---|---|
| LRU (Least Recently Used) | Remove o bloco há mais tempo sem acesso | Tende a funcionar bem quando há forte localidade temporal |
| FIFO | Remove o bloco carregado há mais tempo | Simples de implementar |
| LFU (Least Frequently Used) | Remove o bloco com menos acessos acumulados | Pode preservar blocos antigos que já perderam utilidade |
| Aleatório | Escolha aleatória | Hardware simples |
Sobre o LRU
O LRU costuma ser uma boa estratégia porque se aproxima do princípio da localidade temporal. Ainda assim, implementações reais muitas vezes usam aproximações do LRU, especialmente em caches maiores, para reduzir o custo do hardware de controle.
Políticas de escrita #
Ler da cache é simples: basta verificar se o bloco está presente. Escrever é mais delicado, porque uma atualização feita na cache pode deixar a Memória Principal com uma cópia desatualizada. As políticas de escrita definem como essa sincronização será tratada.
Write Through #
- Toda escrita atualiza cache e Memória Principal ao mesmo tempo
- Mantém a MP sempre coerente com a cache
- Simples de entender e implementar
- Pode aumentar bastante o tráfego de escrita para a MP
Write Back #
- A escrita atualiza apenas a cache
- O bloco recebe uma marca de modificação (dirty bit)
- A MP só é atualizada quando esse bloco for removido da cache
- Reduz o tráfego de escrita, mas exige controle adicional
Write Once #
- A primeira escrita em um bloco é feita como write through
- As escritas seguintes podem ser tratadas como write back
Observação sobre Write Once
O write once aparece com frequência em abordagens didáticas e históricas de coerência de cache. Em sistemas modernos com múltiplos núcleos, a coerência entre caches costuma ser tratada por protocolos específicos de hardware.
Coerência de cache em sistemas multicore
Em sistemas com múltiplos núcleos ou múltiplos processadores, cada núcleo pode manter cópias locais de um mesmo bloco em sua própria cache. Se um deles modifica esse bloco, as demais cópias podem ficar desatualizadas. Esse é o problema de coerência de cache.
As políticas de escrita influenciam esse cenário, mas não o resolvem sozinhas. Em arquiteturas modernas, a coerência costuma depender também de mecanismos específicos do hardware de cache.
A literatura clássica, como apontado no livro de William Stallings, demonstra que aproximadamente 15% de todas as operações de memória são escritas — já que a esmagadora maioria dos acessos consiste em leituras para buscar instruções e dados. Portanto, o write through (especialmente aliado a um write buffer) é geralmente suficiente para muitos sistemas de propósito geral.
Organização física da memória #
A organização física em 1D e 2D é um detalhe importante de implementação de memória, mas aqui ela deve ser entendida como um pano de fundo de hardware para chips de memória em geral, e não como o núcleo do funcionamento lógico da cache.
Independentemente de estarmos falando de Cache ou de Memória Principal, no nível mais baixo do hardware, bilhões de bits precisam ser guardados em transistores dentro de chips de silício. A forma como esses circuitos são desenhados para que um endereço encontre sua célula física ocorre de duas maneiras principais:
Tipo 1D — Seleção linear #
- O endereço aciona diretamente uma entre \(2^E\) saídas do decodificador
- Conceitualmente simples
- Escala mal para valores grandes de \(E\)
Tipo 2D — Matriz linha/coluna #
- O endereço é dividido entre linha e coluna
- A célula é selecionada no cruzamento entre elas
- Reduz drasticamente o tamanho dos decodificadores
Exemplo com \(E = 14\) bits:
$$7\ \text{bits de linha} + 7\ \text{bits de coluna} \implies 128 \times 128 = 16K\ \text{células}$$
graph TD
ADDR["Endereço: 14 bits"]
DL["Decodificador de Linha
7 bits → 128 saídas"]
DC["Decodificador de Coluna
7 bits → 128 saídas"]
CEL["Célula selecionada
Cruzamento linha × coluna"]
ADDR -->|"bits 13 a 7"| DL
ADDR -->|"bits 6 a 0"| DC
DL --> CEL
DC --> CEL
| Organização | Saídas do decodificador (\(E = 14\)) | Eficiência de hardware |
|---|---|---|
| 1D (linear) | \(2^{14} = 16.384\) saídas | Baixa |
| 2D (matriz) | \(2^7 + 2^7 = 256\) saídas | Alta |
Conclusão e próximos artigos #
A cache é um dos projetos mais elegantes da arquitetura de computadores: um componente pequeno, rápido e caro que, ao ser bem posicionado na hierarquia de memória, multiplica a eficiência de todo o sistema sem exigir alterações no software. Cada decisão de projeto — tipo de mapeamento, algoritmo de substituição, política de escrita — reflete um compromisso entre desempenho, custo e complexidade de implementação.
No próximo artigo, falaremos de CPU. Os componentes que formam a unidade central de processamento, como eles se interligam e o que acontece passo a passo quando uma instrução é buscada e executada.
Até lá.


