
Na apresentação desta série, descrevemos o que acontece nos nanossegundos entre apertar Enter e ver o resultado de um programa. Antes de qualquer processamento, porém, há uma questão prévia: dados e instruções precisam estar acessíveis ao processador. É aí que entra a memória.
“Memória” não é um componente único — é toda uma arquitetura de armazenamento projetada para equilibrar três forças em tensão permanente: velocidade, capacidade e custo. Memória rápida o suficiente para o processador (SRAM) é cara demais para volumes grandes; memória barata (DRAM, discos) é lenta demais para acompanhar o processador. A engenharia de computadores resolveu isso com a hierarquia de memória: usar vários tipos ao mesmo tempo, cada um no papel que lhe cabe.
Neste artigo você vai entender:
- o que a memória faz e quais são suas unidades fundamentais;
- como a hierarquia de memória é organizada e por que cada nível existe;
- as fórmulas que determinam o tamanho de endereços, registradores e barramentos de qualquer sistema de memória;
- como a CPU e a memória se comunicam por meio de registradores dedicados e barramentos;
- as operações de leitura e escrita em notação formal;
- as tecnologias SRAM, DRAM e ROM e o mecanismo de correção de erros ECC.
Conceitos fundamentais #
A memória é o componente do sistema computacional responsável por armazenar informações que serão manipuladas pelo processador (UCP).
Operações básicas #
| Operação | Nome técnico | Descrição |
|---|---|---|
| Armazenar | Escrita (write) | Gravar informação na memória |
| Recuperar | Leitura (read) | Obter informação da memória |
Unidades de armazenamento #
Para facilitar o entendimento antes de entrarmos nos jargões técnicos, imagine a memória como um gigantesco depósito com milhares de armários (ou uma imensa biblioteca). O depósito inteiro é a memória do seu computador.
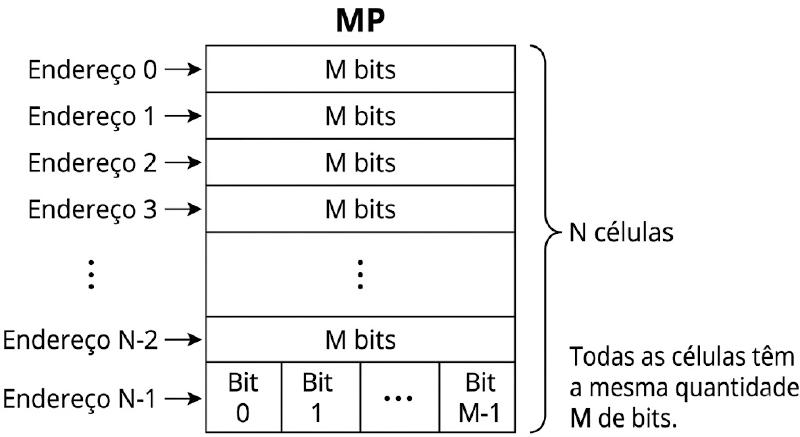
A figura abaixo ilustra essa analogia: um depósito com milhares de armários, onde cada armário representa uma célula de memória — um espaço numerado, de tamanho fixo, pronto para guardar uma quantidade exata de informação.

Cada armário individual, com espaço exato para guardar uma quantidade específica de itens, é o que chamamos de célula. Para que o processador consiga guardar e recuperar informações rapidamente sem precisar revirar o depósito inteiro, cada armário tem um número único pintado em sua porta — esse é o endereço. Quando o computador precisa ler ou escrever um dado, ele não procura o dado pelo que ele é, mas sim pelo endereço de onde ele deve estar, indo direto ao armário correto.
Com essa imagem em mente, fica mais fácil entender as unidades formais que definem esse “depósito”:
| Unidade | Definição |
|---|---|
| Bit | Elemento básico; assume apenas os valores 0 ou 1 |
| Célula | Grupo de bits tratados em conjunto; unidade de armazenamento e transferência |
| Endereço | Número que identifica unicamente cada célula na memória |
| Palavra (word) | Unidade de informação do sistema UCP/MP; representa um número ou instrução |
Relação entre endereços e células
Com \(E\) bits de endereço, a memória pode endereçar \(N = 2^E\) células distintas. Portanto: \(E = \log_2 N\).
A memória é organizada como um array unidimensional de células, cada uma com um endereço único. O processador acessa a memória usando esses endereços, lendo ou escrevendo dados em células específicas. A figura abaixo mostra como a informação é localizada na memória: o processador fornece um endereço, a memória localiza a célula correspondente e realiza a operação de leitura ou escrita.
Hierarquia de memória #
A hierarquia de memória é uma estrutura organizacional que classifica os diferentes tipos de memória em níveis, com base em suas características de velocidade, custo e capacidade.
O objetivo dessa hierarquia é otimizar o desempenho do sistema, garantindo que o processador tenha acesso rápido aos dados mais frequentemente usados, enquanto os dados menos acessados são armazenados em memórias mais lentas e baratas. A seguir, apresentamos os níveis típicos da hierarquia de memória, do mais rápido e caro ao mais lento e barato:
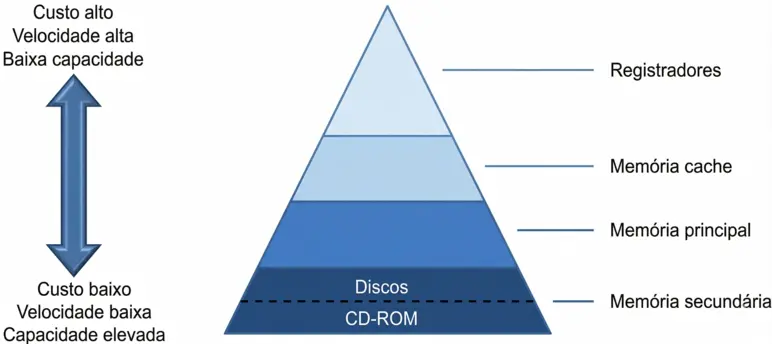
Para materializar essa pirâmide, a tabela abaixo detalha as tecnologias físicas usadas em cada camada, mostrando como a velocidade e o custo se comportam na prática:
| Nível | Tecnologia típica | Velocidade relativa | Custo/bit | Volatilidade | Exemplo |
|---|---|---|---|---|---|
| Registradores | Circuitos internos do processador | Muito alta | Muito alto | Volátil | Registradores da CPU |
| Cache L1/L2/L3 | SRAM | Muito alta | Alto | Volátil | Cache interna do processador |
| Memória principal | DRAM | Alta a moderada | Médio | Volátil | RAM |
| Armazenamento secundário | Flash / magnético | Menor | Baixo | Não volátil | SSD, NVMe, HDD |
Para fins didáticos, mídias como CD-ROM podem aparecer em classificações tradicionais, mas hoje SSDs e HDDs representam melhor o armazenamento secundário encontrado em computadores reais.
Parâmetros de análise de memória #
- Tempo de acesso: intervalo entre o pedido e a disponibilização do dado
- Capacidade: quantidade total de informação armazenável
- Tecnologia de fabricação: semicondutor, magnético, óptico, etc.
- Temporariedade: volátil (perde dados sem energia) × não volátil
- Custo: preço por byte
Embora o computador utilize todos esses níveis em conjunto para equilibrar custo e velocidade, o verdadeiro “palco” onde a execução dos programas acontece é a Memória Principal (RAM). Por isso, a partir de agora, deixaremos os discos e caches de lado para focar exclusivamente em como essa memória principal é estruturada por dentro.
Organização da memória principal #
A memória principal pode ser descrita como um conjunto de \(N\) células, cada uma com \(M\) bits. O endereço identifica a célula que será acessada, enquanto a palavra (word) é a unidade natural de processamento da UCP. Essas duas ideias nem sempre coincidem: uma palavra pode ocupar uma ou mais células, dependendo da arquitetura.
Fórmulas fundamentais #
$$N = 2^E \qquad\qquad E = \log_2 N \qquad\qquad T = N \times M$$onde:
- \(N\) = número de células
- \(E\) = número de bits do endereço (= tamanho do REM)
- \(M\) = número de bits por célula (= tamanho da palavra / RDM)
- \(T\) = total de bits armazenados na memória
Célula, palavra e unidade de transferência #
Em muitos sistemas, a célula tem 8 bits = 1 byte, mas isso não significa que a palavra do processador também tenha 8 bits. A célula é a unidade de armazenamento endereçável; a palavra é a unidade natural de processamento da UCP; e a unidade de transferência é a quantidade de bits movimentada em uma operação de leitura ou escrita.
Palavra ou word é a quantidade de bits que a CPU trata como sua unidade
natural de processamento. Historicamente, isso variou bastante; em arquiteturas
atuais de propósito geral, costuma estar associado a 16, 32 ou 64 bits. Por
exemplo, numa CPU “32-bit”, a largura natural dos registradores inteiros e das
operações inteiras costuma ser de 32 bits (4 bytes).
A palavra tem implicações práticas importantes. Frequentemente sua largura coincide com a dos registradores inteiros da CPU, embora isso não signifique que todos os registradores da arquitetura tenham necessariamente esse tamanho. Outra consequência é o alinhamento: muitas arquiteturas preferem armazenar palavras em endereços múltiplos do seu tamanho (por exemplo, palavras de 4 bytes em endereços múltiplos de 4), o que permite acessos mais eficientes; acessos desalinhados podem exigir múltiplos ciclos ou tratamento especial.
Além disso, a ordem dos bytes dentro de uma palavra é determinada pela
endianness (little-endian ou big-endian). Enquanto a memória armazena bytes, a
interpretação desses bytes como uma palavra depende dessa convenção.
Endianness é a convenção que define a ordem em que os bytes de um valor com
mais de 1 byte são armazenados na memória. No formato little-endian, o byte
menos significativo vem primeiro; no big-endian, o byte mais significativo
vem primeiro. Por exemplo, o valor hexadecimal 0x12345678 seria armazenado
como 78 56 34 12 em little-endian e como 12 34 56 78 em big-endian. Isso não
altera o valor em si, mas afeta como os bytes são interpretados ao ler ou
transmitir dados binários.
Por fim, existe distinção entre endereçamento por byte e por palavra: em arquiteturas com endereçamento por byte, cada endereço refere-se a um byte; em arquiteturas com endereçamento por palavra, cada endereço refere-se a uma palavra inteira.
A unidade de transferência também pode diferir da palavra. Por exemplo, a largura do barramento de dados define quantos bits podem ser transferidos por operação no barramento, e uma linha de cache define a unidade de transferência entre níveis da hierarquia de memória. Em ambos os casos, essa escolha afeta latência, throughput e o projeto do sistema.
Na prática, é comum que uma palavra ocupe múltiplas células:
| Tamanho da palavra | Número de células de 8 bits |
|---|---|
| 8 bits | 1 célula |
| 16 bits | 2 células |
| 32 bits | 4 células |
| 64 bits | 8 células |
Por isso, convém evitar dizer que “\(M\) é ao mesmo tempo o tamanho da célula, da palavra e do RDM”, porque isso só vale em arquiteturas específicas.
A maioria dos sistemas modernos adota o byte como unidade básica de armazenamento.
Prefixos de capacidade (potências de 2) #
Como a quantidade de células em uma memória RAM moderna chega facilmente à casa dos bilhões, utilizamos prefixos multiplicativos baseados em potências de 2 para simplificar a notação matemática:
| Prefixo | Símbolo | Valor |
|---|---|---|
| Kilo | K | \(2^{10} = 1.024\) |
| Mega | M | \(2^{20} \approx 10^6\) |
| Giga | G | \(2^{30} \approx 10^9\) |
| Tera | T | \(2^{40} \approx 10^{12}\) |
| Peta | P | \(2^{50} \approx 10^{15}\) |
Observe na tabela acima que, embora os prefixos sejam similares aos usados no SI, seus valores são baseados em potências de 2, não de 10. Por exemplo, 1 KB (kilobyte) é \(2^{10} = 1.024\) bytes, e não exatamente 1.000 bytes. Essa convenção é importante para evitar confusões, especialmente quando falamos de capacidades de memória e armazenamento.
Agora que sabemos como dimensionar o tamanho e a capacidade dessa memória, surge um problema prático: como o processador (que é extremamente rápido) consegue “conversar” com a memória principal para ler e escrever esses bilhões de bits sem se perder? É aqui que entram componentes dedicados a fazer essa ponte de comunicação.
Registradores e barramentos #
A comunicação entre UCP e memória principal é feita por registradores dedicados e por barramentos.
- O REM (Registrador de Endereços da Memória) guarda o endereço da célula a ser acessada.
- O RDM (Registrador de Dados da Memória) guarda o dado que será lido da memória ou escrito nela.
- O barramento de endereços transporta endereços.
- O barramento de dados transporta os dados.
- O barramento de controle transporta sinais como leitura, escrita e espera.
Esses elementos existem para organizar e viabilizar a comunicação entre processador e memória de forma controlada.
Para que a CPU não precise lidar diretamente com a lentidão da memória, o tempo todo, ela delega a comunicação para “salas de espera” internas, os registradores (REM e RDM). Esses registradores enviam e recebem dados através de vias de comunicação eletrônicas chamadas barramentos.
A figura a seguir ilustra o modelo de comunicação entre a Unidade Central de Processamento (UCP) e a Memória Principal (MP). Essa integração é realizada por meio de três vias estruturais que compõem o barramento do sistema:
- Barramento de Endereços: Conecta-se ao REM (Registrador de Endereços da Memória) da UCP e tem a função de transportar a localização exata da célula de memória que será acessada.
- Barramento de Dados: Conecta-se ao RDM (Registrador de Dados da Memória) e é a via por onde a informação (o conteúdo em si) trafega em direção à memória (escrita) ou vindo dela (leitura).
- Barramento de Controle: Conecta-se à UC (Unidade de Controle) e é responsável por transmitir os sinais de comando, como as ordens de “ler” ou “gravar”, além de sincronizar a operação.
Do lado direito, o diagrama mostra que a Memória Principal não se conecta diretamente aos fios do barramento, mas utiliza um Controlador de memória. Esse controlador atua como uma interface que decodifica os sinais de endereço e controle recebidos da UCP para, então, permitir o fluxo dos dados de ou para a MP.
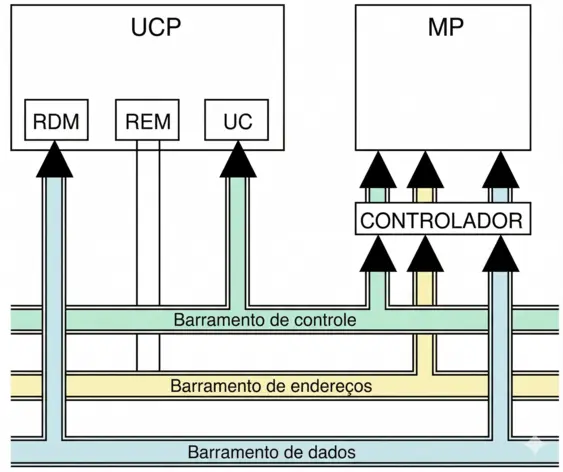
Cada componente ilustrado no esquema acima possui uma responsabilidade estrita para garantir que a informação trafegue sem erros. Resumimos a função e a capacidade de cada via e “sala de espera” a seguir:
| Componente | Função | Tamanho |
|---|---|---|
| REM | Armazena o endereço da célula a ser acessada | \(E\) bits |
| RDM | Armazena o dado em transferência (leitura ou escrita) | \(M\) bits |
| BE — Barramento de Endereços | Liga REM → Controlador → MP (unidirecional) | \(E\) bits |
| BD — Barramento de Dados | Liga RDM ↔ MP (bidirecional) | \(M\) bits |
| BC — Barramento de Controle | Sinais de controle: leitura, escrita, wait | Variável |
Linguagem de Transferência entre Registradores (LTR) #
A LTR é uma notação formal para descrever operações de transferência de dados entre registradores e memória.
| Notação | Significado |
|---|---|
| \((X)\) | Conteúdo do registrador ou posição de memória \(X\) |
| \((X) \leftarrow (Y)\) | Copiar conteúdo de \(Y\) para \(X\) |
| \((MP[REM])\) | Conteúdo da célula cujo endereço está armazenado no REM |
Exemplos de notação LTR:
- \((REM) \leftarrow (CI)\): copia o conteúdo do Contador de Instrução para o REM
- \((RDM) \leftarrow (MP[REM])\): lê da MP a célula apontada pelo REM e coloca no RDM
- \((MP[REM]) \leftarrow (RDM)\): escreve na MP o conteúdo do RDM na posição indicada pelo REM
Operações de leitura e escrita #
Para esta seção, vamos usar a notação LTR para descrever passo a passo como as operações de leitura e escrita acontecem na prática, desde o momento em que a UCP decide acessar a memória até a entrega do dado ou a gravação na MP. Veja novamente o diagrama de interconexão entre UCP e MP para acompanhar os passos descritos a seguir.
Leitura (Read) #
A operação de leitura é um processo estruturado em quatro etapas. O processador informa onde quer ler, aciona o comando e aguarda a chegada da informação. Veja o fluxo exato de como isso acontece:
| Passo | Operação LTR | Descrição |
|---|---|---|
| 1 | \((REM) \leftarrow \text{endereço desejado}\) | O endereço é carregado no REM |
| 2 | Sinal de LEITURA no BC | O controlador interpreta a solicitação |
| 3 | \((RDM) \leftarrow (MP[REM])\) | O conteúdo da célula é transferido para o RDM |
| 4 | Registrador da UCP \(\leftarrow (RDM)\) | O dado é entregue ao processador |
A operação de leitura é não destrutiva: o dado permanece na MP mesmo após ser lido. O processador pode ler a mesma célula várias vezes sem alterar seu conteúdo, o que é fundamental para a execução de programas que dependem de dados estáveis na memória.
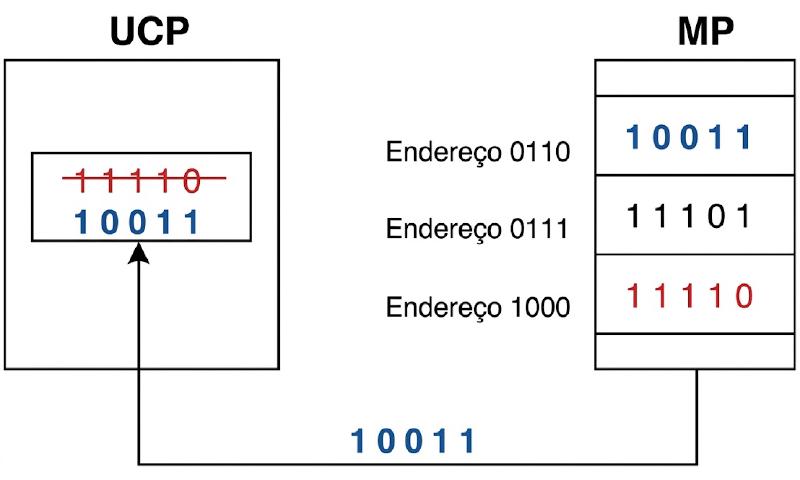
A figura abaixo ilustra o processo de leitura. O valor 10011, armazenado no
endereço da MP 0110, é transferido para um registrador da UCP, sobrescrevendo
aí o valor anterior do registrador (11110).
Escrita (Write) #
Enquanto na leitura o processador apenas pede um dado, na operação de escrita ele precisa fornecer duas coisas ao mesmo tempo: o endereço de destino e a informação a ser salva. O sequenciamento lógico ocorre da seguinte maneira:
| Passo | Operação LTR | Descrição |
|---|---|---|
| 1 | \((REM) \leftarrow \text{endereço}\) | O endereço de destino é carregado no REM |
| 2 | \((RDM) \leftarrow \text{dado}\) | O dado a ser gravado é carregado no RDM |
| 3 | Sinal de ESCRITA no BC | O controlador recebe o comando de gravação |
| 4 | \((MP[REM]) \leftarrow (RDM)\) | O dado é gravado na célula indicada |
A figura abaixo ilustra o processo de escrita. O valor 11110 é transferido
(uma cópia) da UCP para a MP e armazenado na célula de endereço 1000,
apagando o conteúdo anterior (00110).
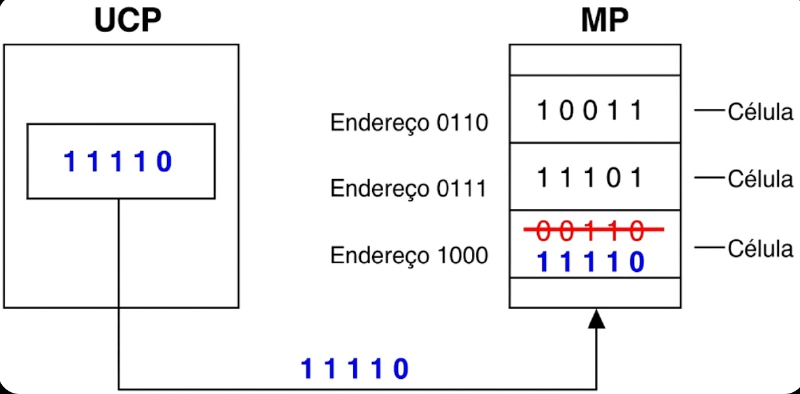
Escrita é uma operação destrutiva
A escrita apaga permanentemente o conteúdo anterior da célula sem possibilidade de recuperação. A leitura, ao contrário, é não destrutiva: o dado permanece na MP após ser copiado para o RDM.
Dimensionamento em prática #
Com as fórmulas \(N = 2^E\), \(E = \log_2 N\) e \(T = N \times M\) em mãos, percorremos uma série de variações — cada uma introduz uma nova forma de apresentar o problema ou um novo conjunto de grandezas fornecidas.
Exemplo — Parâmetros a partir de N e M
Uma MP tem \(N = 2K\) células de \(M = 16\) bits. Determine \(E\) (tamanho do REM) e \(T\).
\(N = 2K = 2 \times 2^{10} = 2^{11}\) células
\(E = \log_2(2^{11}) = 11\) bits → REM = 11 bits
\(T = N \times M = 2^{11} \times 16 = 2^{15} = \mathbf{32K}\) bits
Exemplo 2 — Descobrindo a quantidade de células
Dados: \(T = 256K\) bits, \(M = 8\) bits. Determine \(N\) e \(E\).
$$N = \frac{T}{M} = \frac{2^{18}}{2^3} = 2^{15} = 32K \text{ células}$$Como \(N = 2^{15}\), sabemos que \(E = 15\) bits.
Exemplo 3 — Trabalhando com “palavras” em vez de bits
Cuidado com as unidades! Aqui a capacidade é dada em palavras, não em bits soltos. Dados: MP com 2K palavras de 16 bits. Determine \(E\), tamanho do RDM, maior endereço e \(T\).
- \(N = 2K = 2^{11}\) palavras → \(E = 11\) bits (tamanho do REM)
- RDM = 16 bits (= tamanho da palavra, M)
- Maior endereço: \(N - 1 = 2048 - 1 = \mathbf{2047}\)
- \(T = 2^{11} \times 16 = 32K\) bits
Exemplo 4 — Lendo múltiplas células por acesso
Arquiteturas mais modernas podem ler várias células de uma vez para ganhar tempo. Dados: RDM = 32 bits, REM = 24 bits, 2 células por acesso.
- Número de posições endereçáveis: \(N = 2^{24} = 16M\)
- RDM = 32 bits traz 2 células → cada célula = \(32 / 2 = 16\) bits
- \(T = 2^{24} \times 16 = 2^{28} = 256M\) bits
- Palavra = RDM = 32 bits
Exemplo 5 — Barramentos largos e células fracionadas
Um cenário avançado onde a capacidade total e os barramentos ditam as regras. Dados: BE = 33 bits, BD transfere 4 palavras, célula = 1/8 de palavra, \(T = 64G\) bits.
- \(N = 2^{33} = 8G\) células
- \(M = T / N = 64G / 8G = 8\) bits por célula
- Como 1 célula = 1/8 palavra → palavra = \(8 \times 8 = 64\) bits
- Largura do BD = \(4 \text{ palavras} \times 64 = \mathbf{256}\) bits
Python: calculando parâmetros de memória #
O código abaixo implementa uma função memoria_params que calcula os parâmetros
básicos de memória a partir de diferentes combinações de entradas. Ela verifica
a consistência dos dados e retorna um dicionário com os valores calculados.
import math
from typing import Optional
def _is_power_of_two(value: int) -> bool:
return value > 0 and (value & (value - 1)) == 0
def memoria_params(
N: Optional[int] = None,
E: Optional[int] = None,
M: Optional[int] = None,
T: Optional[int] = None,
) -> dict[str, int]:
"""
Calcula parâmetros básicos de memória.
Parâmetros:
N: número de células
E: número de bits de endereço
M: número de bits por célula
T: capacidade total em bits
É necessário informar exatamente dois parâmetros compatíveis.
"""
provided = {k: v for k, v in {"N": N, "E": E, "M": M, "T": T}.items() if v is not None}
if len(provided) != 2:
raise ValueError("Informe exatamente dois parâmetros.")
if N is not None and M is not None:
if not _is_power_of_two(N):
raise ValueError("N deve ser potência de 2.")
E = int(math.log2(N))
T = N * M
elif E is not None and M is not None:
N = 2 ** E
T = N * M
elif T is not None and M is not None:
if T % M != 0:
raise ValueError("T deve ser divisível por M.")
N = T // M
if not _is_power_of_two(N):
raise ValueError("N deve ser potência de 2.")
E = int(math.log2(N))
elif N is not None and T is not None:
if T % N != 0:
raise ValueError("T deve ser divisível por N.")
M = T // N
if not _is_power_of_two(N):
raise ValueError("N deve ser potência de 2.")
E = int(math.log2(N))
else:
raise ValueError("Combinação de parâmetros não suportada.")
return {"N": N, "E": E, "M": M, "T": T}
# Exemplo 1: N = 2K = 2^11, M = 16 bits
resultado = memoria_params(N=2**11, M=16)
print(resultado) # {'N': 2048, 'E': 11, 'M': 16, 'T': 32768}SRAM, DRAM e ROM #
As principais tecnologias discutidas em cursos introdutórios de arquitetura são SRAM, DRAM e ROM.
- SRAM (Static RAM): mais rápida e mais cara; muito usada em memórias cache.
- DRAM (Dynamic RAM): mais lenta e mais barata; usada como memória principal.
- ROM (Read-Only Memory): memória não volátil empregada para armazenar firmware.
A diferença entre SRAM e DRAM está na forma de armazenamento de cada bit. A SRAM usa circuitos mais complexos por bit, o que a torna rápida, mas cara e menos densa. Já a DRAM armazena bits em capacitores, que precisam ser recarregados periodicamente por meio de refresh (recarregamento). Isso a torna mais lenta, porém muito mais econômica para grandes capacidades.
A escolha entre elas depende inteiramente de onde a memória será instalada e qual será sua função no sistema:
| Tipo | Velocidade | Custo | Refresh | Aplicação principal |
|---|---|---|---|---|
| SRAM (Static RAM) | Mais rápida | Mais cara | Não necessita | Cache L1/L2 |
| DRAM (Dynamic RAM) | Mais lenta | Mais barata | Necessário (periódico) | MP convencional |
| ROM (Read Only Memory) | Leitura rápida | Variável | Não necessita | BIOS, firmware |
Afinal, por que a SRAM é tão mais cara e rápida, enquanto a DRAM exige esse refresh (atualização)? A resposta está na física da coisa. A SRAM usa um circuito complexo (geralmente com seis transistores) para cada bit. Isso a torna ultra-rápida e estável, mas ocupa muito espaço físico e custa caro.
Já a DRAM guarda cada bit de forma mais engenhosa e simples: como uma minúscula carga elétrica em um capacitor. O problema? Esse capacitor “vaza” energia com o tempo. Por isso, o sistema precisa ler e regravar (dar o refresh) nessa memória milhares de vezes por segundo para não perder os dados. É essa necessidade de manutenção constante que a torna um pouco mais lenta. Em compensação, seu design simples permite alojar bilhões de capacitores em um espaço pequeno, criando pentes de memória com gigabytes de capacidade a um custo super acessível.
ROM, firmware, BIOS e UEFI #
Didaticamente, a ROM é apresentada como uma memória não volátil usada para armazenar instruções permanentes de inicialização do sistema. Em computadores atuais, porém, é mais preciso falar em firmware armazenado em memória flash, normalmente associado à UEFI, enquanto o termo BIOS aparece mais como referência histórica ou de compatibilidade.
Assim, em vez de dizer que “a ROM não pode ser reescrita”, é melhor formular de modo mais técnico:
Memórias não voláteis usadas para firmware não são destinadas à escrita comum pela UCP durante a execução normal do sistema, mas isso não significa imunidade absoluta a falhas ou adulterações. Seu papel principal é armazenar código de inicialização e configuração de baixo nível.
Principais aplicações:
- BIOS (Basic Input/Output System)
- Bootstrap / IPL (Initial Program Load) — programa que inicializa o sistema
- Firmware: forno de micro-ondas, videogames, injeção eletrônica automotiva
Erros na memória e ECC #
Memórias reais estão sujeitas a falhas ocasionais, como inversões de bits (bit flips) causadas por ruído elétrico, interferência eletromagnética, defeitos físicos ou partículas de alta energia. Para reduzir os efeitos desses problemas, alguns sistemas empregam ECC (Error Correction Code).
O ECC adiciona bits de controle aos dados armazenados ou transferidos, permitindo:
- detectar certos erros;
- corrigir automaticamente erros simples de bit;
- aumentar a confiabilidade do sistema.
Esse mecanismo é especialmente importante em ambientes onde integridade e disponibilidade são críticas, como servidores, estações de trabalho de alta confiabilidade e sistemas científicos.
O mecanismo ECC detecta e corrige esses erros:
%%{init: {'flowchart': {'useMaxWidth': false}}}%%
graph TB
D["M bits de dados"]
A1["Algoritmo A
gera K1 bits de controle"]
GR["Grava M + K1 bits na MP"]
LE["Leitura:
M bits + K1 bits armazenados"]
A2["Algoritmo A
gera K2 bits de controle"]
CMP{"K1 = K2?"}
OK["Sem erro
Dado correto"]
ERR["Erro detectado
e corrigido"]
D --> A1 --> GR --> LE --> A2 --> CMP
CMP -->|"Sim"| OK
CMP -->|"Não"| ERR
No fluxo acima, o “Algoritmo A” é uma implementação matemática, baseada em Teoria da Informação. Funciona adicionando bits extras (bits de redundância ou controle) aos dados originais antes de gravá-los.
- Detecção simples (Bit de Paridade): O algoritmo mais básico apenas conta
quantos bits
1existem na palavra e adiciona um bit extra para que o total seja sempre par (paridade par). Se na leitura o número de1s for ímpar, o sistema sabe que um bit virou. O problema? Ele avisa que tem erro, mas não sabe qual bit errou, impossibilitando a correção. - Correção ativa (Código de Hamming): Para poder corrigir, o mecanismo ECC usa algoritmos mais sofisticados, como o Código de Hamming. Ele entrelaça vários bits de paridade dentro da mesma palavra. Se um bit sofrer flip, a combinação dos erros nas paridades aponta exatamente a posição do bit defeituoso. Sabendo qual bit está errado, a memória simplesmente o inverte de volta para o valor correto, entregando a informação intacta à CPU.
O preço da segurança: ECC na prática
Se o ECC é tão bom, por que não vem em todo computador? O motivo é o custo triplo: espaço, dinheiro e tempo. Para cada 64 bits de dados, um módulo ECC precisa de 8 bits extras físicos apenas para o controle, o que encarece a fabricação. Além disso, calcular a redundância na entrada e na saída adiciona uma leve latência.
Por isso, memórias padrão de desktops preferem a velocidade e o baixo custo (um pixel errado num jogo não é o fim do mundo). Já as memórias ECC são o padrão absoluto em servidores, datacenters e sistemas críticos, onde um bit trocado silenciosamente pode corromper um banco de dados inteiro ou alterar um valor financeiro.
O suposto bit flip de um speedrun de Super Mario 64 #
Como vimos na seção anterior, a memória não é um ambiente blindado e perfeito. O tráfego de dados no barramento e até mesmo o armazenamento nas células estão sujeitos a interferências físicas que causam o flip de bits (um \(0\) que vira \(1\), ou vice-versa). Mas o que causa isso? Pode ser desde ruído eletromagnético de componentes próximos, flutuações na rede elétrica, até raios cósmicos (partículas subatômicas de alta energia vindas do espaço que colidem com o chip de memória).
Muitos talvez já tenham ouvido falar de bit flip por conta de um curioso episódio na comunidade de speedrunning de Super Mario 64. Para quem não sabe, speedrunning é a prática de completar um jogo no menor tempo possível, e Super Mario 64 é um dos jogos mais populares para isso.
Um dos mitos mais persistentes na comunidade de speedrunning de Super Mario 64 é a alegação de que um raio cósmico teria causado um erro de upwarp (um teletransporte vertical inesperado) na fase Tick Tock Clock durante uma corrida em 2013. Embora o fenômeno tenha ganhado fama na internet como um exemplo de interferência espacial em hardware eletrônico, especialistas em desmontagem de código e hardware do console Nintendo 64 argumentam que não há evidências que sustentem essa teoria. Em vez de partículas ionizadas do espaço, a explicação técnica mais provável reside em falhas físicas comuns, como conexões de pinos sujas, mau contato no slot do cartucho ou o desgaste natural dos componentes do aparelho ao longo de décadas.
A popularização dessa teoria como um fato científico é atribuída a uma sucessão de falhas no jornalismo especializado em jogos, que amplificou a hipótese sem verificar a veracidade técnica junto à comunidade de TASers (Tool-Assisted Speedrunners — jogadores que utilizam ferramentas de assistência). A narrativa ganhou força viral através de redes sociais e citações em canais educacionais de grande alcance, como o Veritasium, sem a devida análise crítica, criando um ciclo de desinformação. Hoje, o caso serve como um estudo de caso sobre como teorias atraentes, porém incorretas, podem se tornar verdades aceitas pelo público casual, frustrando especialistas que buscam analisar anomalias em jogos clássicos com rigor científico e técnico.
O vídeo abaixo mostra a explicação detalhada do fenômeno, desmontando o mito do bit flip e apresentando as evidências técnicas que apontam para causas mais plausíveis. Vale a pena assistir para entender como a comunidade de speedrunning e especialistas em hardware chegaram a essa conclusão.
Python: Simulando um bit de paridade #
Para tirar o conceito da teoria, veja um exemplo simplificado em Python que
implementa a lógica por trás do bit de paridade par. O objetivo é garantir que a
palavra final transmitida sempre tenha uma quantidade par de números 1.
def adicionar_paridade_par(dados):
"""Calcula e adiciona o bit de paridade par a uma string de bits."""
quantidade_uns = dados.count('1')
bit_paridade = '0' if quantidade_uns % 2 == 0 else '1'
return dados + bit_paridade
def verificar_erro(dado_recebido):
"""Verifica se o dado recebido possui erro usando paridade par."""
quantidade_uns = dado_recebido.count('1')
if quantidade_uns % 2 != 0:
return "Erro detectado! O dado foi corrompido."
return "Dado aparentemente íntegro (sem erros de 1 bit)."
# --- Simulando na prática ---
# 1. CPU quer gravar o dado "1011001" (possui quatro números '1')
dado_original = "1011001"
dado_gravado = adicionar_paridade_par(dado_original)
print(f"Dado gravado na memória: {dado_gravado}")
# Resultado esperado: 10110010 (adicionou 0 no final)
# 2. Simular interferência: flipar um bit nos dados (não no bit de paridade)
# vamos flipar o bit de índice 5 (0-based) do bloco de dados
data = dado_gravado[:-1] # parte de dados sem o bit de paridade
parity = dado_gravado[-1] # bit de paridade
i = 5 # índice do bit a ser flipado (0-based)
corrupted_data = data[:i] + ('1' if data[i] == '0' else '0') + data[i+1:]
dado_corrompido = corrupted_data + parity
print(f"Dado lido com defeito: {dado_corrompido}")
# Resultado esperado: 10110110 (agora temos cinco números '1')
# 3. O Controlador de memória faz a checagem
print(f"Status da leitura: {verificar_erro(dado_corrompido)}")
# Resultado esperado: "Erro detectado! O dado foi corrompido."Localidade de acesso: a ponte para a cache #
Os princípios que regem como os programas acessam a memória têm consequências profundas para o projeto do sistema. Dois padrões empíricos se destacam.
O princípio da localidade temporal observa que, se um endereço de memória
foi acessado recentemente, há alta probabilidade de que seja acessado novamente
em breve. A variável de controle de um laço for, por exemplo, é lida e
incrementada a cada iteração — sendo reutilizada repetidamente ao longo de
toda a execução do laço.
O princípio da localidade espacial observa que, se um endereço foi
acessado, é provável que os endereços vizinhos também sejam acessados em
sequência. Ao percorrer um array, o acesso ao elemento a[i] implica alta
probabilidade de acesso a a[i+1] logo em seguida.
Esses dois princípios são a justificativa para a existência da memória cache: ela mantém nos seus slots os dados acessados recentemente (explorando localidade temporal) e carrega blocos inteiros de células contíguas em caso de miss (explorando localidade espacial). Sem esses padrões observáveis nos programas reais, a cache seria inútil. Com eles, a cache consegue antecipar o que o processador precisará — e ter os dados prontos, evitando o acesso lento à DRAM.
Conclusão e próximos artigos #
A memória principal é o substrato sobre o qual toda a execução de programas acontece. Partimos de sua organização mais básica — células, endereços e barramentos — e chegamos às fórmulas que dimensionam qualquer sistema de memória, passando pelas operações de leitura e escrita em notação LTR, pelos tipos de tecnologia disponíveis e pelos princípios de localidade que motivam a hierarquia de cache.
No próximo artigo, veremos como a diferença de velocidade entre CPU e DRAM motivou o surgimento da cache, os três modelos de mapeamento que determinam onde blocos da MP são armazenados, os algoritmos de substituição e as políticas de escrita.
Até lá!


