
No artigo anterior — CPU em Ação: O Processador Hipotético — acompanhamos nosso processador de 12 bits executando uma instrução de cada vez: busca na memória, decodificação, execução, escrita do resultado e recomeço. A sequência é correta e completa, mas carrega uma ineficiência fundamental: enquanto a UAL executa uma instrução, o barramento de memória fica ocioso; enquanto uma nova busca acontece, a UAL espera. É como se uma linha de montagem de automóveis nunca tocasse no próximo carro antes de o anterior estar completamente pronto.
A técnica de pipeline elimina exatamente esse desperdício: assim como uma linha de montagem industrial mantém vários carros em etapas diferentes ao mesmo tempo, o pipeline mantém várias instruções em estágios diferentes do ciclo simultaneamente. O resultado é um aumento expressivo no rendimento (throughput) sem que nenhuma instrução individualmente fique mais rápida, tudo graças à sobreposição de operações.
Neste artigo você vai entender:
- a analogia da linha de montagem e as fórmulas de desempenho;
- os estágios clássicos de pipeline de 2 e 5 fases;
- os três tipos de hazards que interrompem o fluxo do pipeline;
- como calcular o speedup real com exemplos numéricos;
- a hierarquia de barramentos que interliga CPU, memória e periféricos;
- as diferenças entre barramentos síncronos e assíncronos;
- as duas formas de implementar a unidade de controle: cabeada e microprogramada.
A analogia da linha de montagem #
Imagine uma fábrica que monta automóveis em quatro etapas independentes — estrutura, motor, pintura e acabamento — cada uma levando exatamente uma semana. Sem pipeline, o segundo carro só entra na linha quando o primeiro estiver completamente pronto: quatro carros levam 16 semanas. Com pipeline, cada etapa recebe um carro diferente toda semana: após as quatro semanas iniciais de “preenchimento” da linha, um carro sai pronto a cada semana.
| Situação | 1 carro | 4 carros |
|---|---|---|
| Sem pipeline | 4 semanas | 16 semanas |
| Com pipeline | 4 semanas | 7 semanas |
A técnica de pipeline funciona como uma linha de montagem: diferentes instruções ocupam estágios diferentes ao mesmo tempo. O ganho não vem de tornar uma instrução individualmente mais rápida, e sim de aumentar o número de instruções concluídas por unidade de tempo (vazão ou throughput).
Em um modelo idealizado, no qual:
- todos os estágios levam exatamente 1 ciclo;
- não há hazards;
- não há conflitos de recurso;
- o pipeline permanece sempre alimentado,
temos:
$$ T_{\text{sem pipeline}} = N \times K $$$$ T_{\text{com pipeline}} = K + (N - 1) $$onde:
- \(N\) = número de instruções;
- \(K\) = número de estágios do pipeline.
O termo \(K\) representa o tempo de preenchimento inicial da linha. Depois disso, em regime ideal, uma instrução termina por ciclo. O termo \((N-1)\) são os ciclos adicionais após o primeiro estágio estar cheio. Para programas grandes, onde \(N \gg K\), o tempo tende a \(N\) ciclos — ou seja, uma instrução terminada por ciclo.
Essas fórmulas valem para o caso ideal
Em processadores reais, hazards de dados, controle e estrutura podem inserir stalls e flushes, reduzindo o ganho efetivo do pipeline.
O overhead fixo de \(K\) ciclos para preencher o pipeline se dilui à medida que mais instruções são processadas. Para um programa com milhões de instruções, o speedup se aproxima de \(K\) vezes. Para poucas instruções, o custo de inicialização pode tornar o pipeline menos vantajoso do que a execução sequencial.
Para entender, vamos lembrar do ciclo de instrução tradicional visto em artigos anteriores, que é dividido em etapas como busca, decodificação, execução e escrita de resultado. O pipeline divide esse ciclo em estágios que podem ser processados simultaneamente por diferentes instruções.
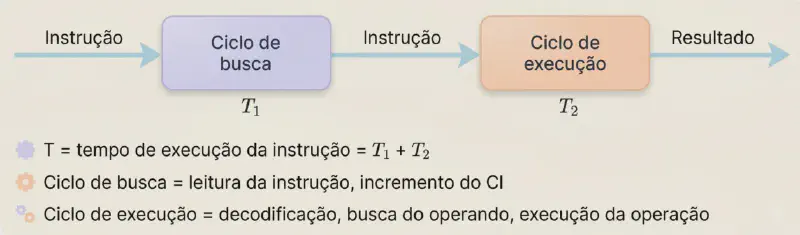
Em uma execução sequencial, cada instrução passa por todas as etapas antes da próxima começar, como ilustrado abaixo:
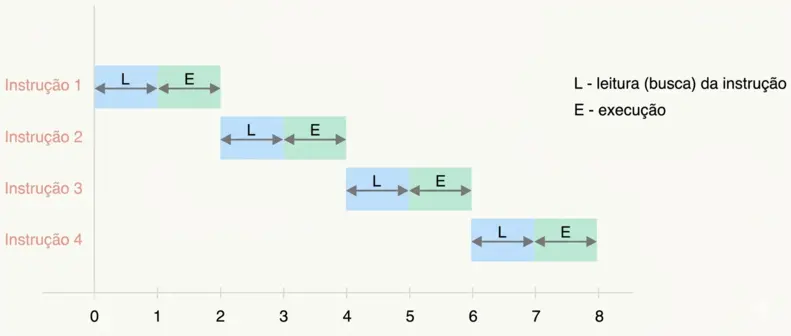
Veja que, supondo que cada estágio gaste o mesmo tempo T, para executar as 4 instruções sequencialmente seriam gastos 8T (4 instruções × 2 estágios cada).
Nas próximas seções, vamos explorar como os estágios do pipeline são organizados e quais desafios surgem quando múltiplas instruções competem por recursos compartilhados.
Os estágios do pipeline #
Pipeline de dois estágios #
A divisão mais simples separa o ciclo em busca (Fetch) e execução (Execute). Enquanto a UAL executa a instrução \(i\), a UC já busca a instrução \(i+1\) na memória — os dois estágios trabalham em paralelo.
| Estágio | Função |
|---|---|
| Fetch (Busca) | Busca a próxima instrução na memória via REM/RDM |
| Execute (Execução) | Decodifica a instrução e executa a operação |
A figura abaixo ilustra o que acontece com o mesmo programa de 4 instruções visto anteriormente, mas agora com o pipeline de 2 estágios. Note que a partir do segundo ciclo, as instruções estão sobrepostas: enquanto a primeira é executada, a segunda já está sendo buscada; quando a segunda é executada, a terceira já está sendo buscada; e assim por diante:
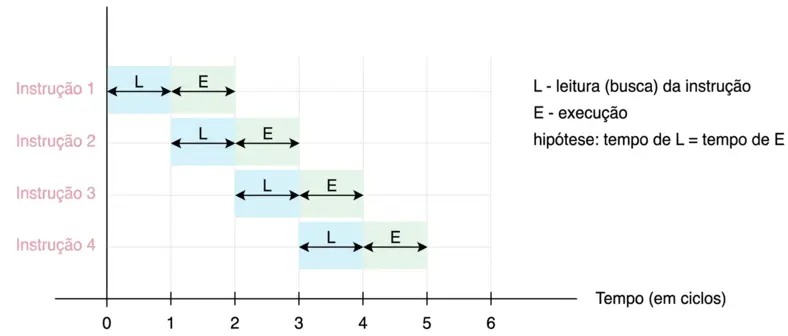
Pela sobreposição, o tempo total para as 4 instruções cai de 8T para 5T — um ganho de 1,6×.
O problema surge nas instruções de desvio condicional (como JZ ou JP do nosso processador hipotético): quando a condição é testada no estágio Execute, a instrução já buscada no estágio Fetch pode ser a instrução errada. É preciso descartá-la (flush) e buscar a instrução no endereço correto do desvio.
A solução mais comum é predição de desvio: assume-se que o desvio não vai ocorrer e continua-se buscando instruções sequencialmente. Se a predição falhar, faz-se o flush e reinicia-se a busca. Predições corretas eliminam a penalidade; predições erradas impõem apenas um ciclo de atraso.
Penalidade de desvio
Em modelos muito simples, a penalidade pode ser de apenas 1 ciclo. Em pipelines mais profundos, a penalidade pode ser maior, porque mais instruções já terão sido parcialmente processadas antes da resolução do desvio.
Pipeline de cinco estágios (RISC clássico) #
Arquiteturas RISC refinaram o pipeline para cinco estágios, tornando cada etapa mais granular — e portanto mais rápida, pois cada estágio exige menos lógica:
flowchart LR
B["B
Busca
(Fetch)"] --> D["D
Decodificação
(Decode)"] --> C["C
Cálculo de
Endereço"] --> O["O
Obtenção do
Operando"] --> E["E
Execução
(Execute)"]
| Estágio | Sigla | Função |
|---|---|---|
| Busca | B | Busca instrução na memória principal (MP) via CI/PC |
| Decodificação | D | Decodifica o código de operação; identifica operandos nos registradores |
| Cálculo de endereço | C | Calcula o endereço efetivo do operando na memória |
| Obtenção do operando | O | Busca o operando na MP ou em registrador |
| Execução | E | Executa a operação na UAL e/ou armazena o resultado |
Com cinco estágios, o pipeline pode manter cinco instruções em andamento simultaneamente — cada uma em um estágio diferente. A frequência do clock pode ser aumentada porque cada estágio é mais simples; e o throughput, em regime estacionário, se aproxima de uma instrução concluída por ciclo.
A figura abaixo mostra o mesmo programa de 4 instruções, agora com o pipeline de 5 estágios. Note que a partir do quinto ciclo, todas as cinco etapas estão ocupadas por diferentes instruções, e a cada ciclo uma nova instrução é completada:
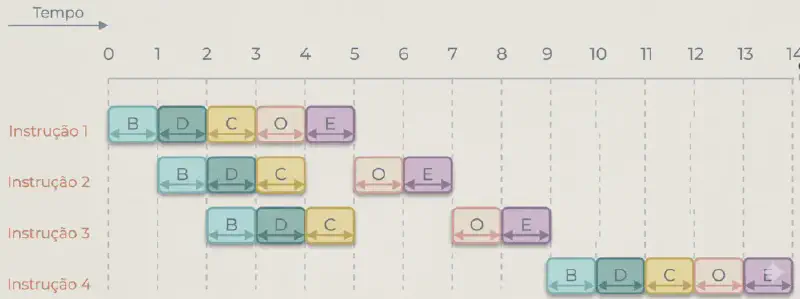
Se o pipeline fosse sequencial, as 4 instruções levariam 20T (4 instruções × 5 estágios cada). Com o pipeline de 5 estágios, o tempo total caiu para 14T — um ganho de aproximadamente 1,43×. Observe que somente um acesso à memória pode ser realizado de cada vez. Logo, durante a execução do estágio de busca de instrução (B), o estágio de obtenção de operando (O) deve esperar, e vice-versa.
Hazards: quando o pipeline tropeça #
O pipeline ideal pressupõe que cada estágio termina no mesmo tempo e que as instruções são independentes entre si. Na prática, três situações quebram essa hipótese — são os chamados hazards:
Quando um hazard é detectado, o pipeline pode precisar de stalls (bolhas — ciclos desperdiçados à espera) ou flushes (descarte de instruções já buscadas). O desempenho real fica abaixo do ideal teórico.
| Tipo | Causa | Solução |
|---|---|---|
| Estrutural | Dois estágios precisam do mesmo recurso de hardware ao mesmo tempo (p. ex., um único banco de memória para busca e para dados) | Duplicar o recurso (cache separada de instrução e de dados); inserir stall |
| Dados | Uma instrução depende do resultado de uma instrução anterior que ainda não completou a execução | Forwarding (antecipação do resultado diretamente entre estágios); stall |
| Controle | Uma instrução de desvio condicional invalida instruções já buscadas | Predição de desvio; flush das instruções incorretas |
Esses hazards são a principal razão pela qual o desempenho real do pipeline fica abaixo do limite teórico.
A maioria das otimizações de compiladores modernos — como reordenação de instruções e loop unrolling — tem como objetivo exatamente reduzir a frequência de hazards de dados e controle.
Calculando o desempenho #
Mesmo com os atrasos causados pelos hazards, a matemática do pipeline ainda prova sua superioridade sobre a execução sequencial em larga escala. Para consolidar esse conceito, os exemplos a seguir ilustram como aplicar as fórmulas na prática. O resultado mais importante não é o número final em si, mas a intuição sobre quando vale a pena (ou não) usar essa técnica.
Exemplo — Pipeline em quatro estágios
Considere uma instrução dividida em 6 blocos com tempos:
$$ A=80,\; B=20,\; C=70,\; D=40,\; E=60,\; F=10\ \text{ps} $$O tempo de execução de uma instrução sem pipeline é a soma de todos os blocos:
$$ T_{\text{instr}} = 80+20+70+40+60+10 = 280\ \text{ps} $$Para 10 instruções executadas sequencialmente, o tempo total será:
$$ T_{\text{seq}} = 10 \times 280 = 2800\ \text{ps} $$Agora, para implementar um pipeline em 4 estágios, agrupamos os blocos de forma a buscar equilibrar os tempos:
- Estágio 1: \(A = 80\) ps
- Estágio 2: \(B + C = 20 + 70 = 90\) ps
- Estágio 3: \(D = 40\) ps
- Estágio 4: \(E + F = 60 + 10 = 70\) ps
O ciclo do pipeline é determinado pelo estágio mais lento:
$$ T_{\text{ciclo}} = \max(80,90,40,70) = 90\ \text{ps} $$Para 10 instruções, o tempo total com pipeline será:
$$ T_{\text{pipeline}} = 4 \times 90 + (10-1)\times 90 $$$$ T_{\text{pipeline}} = 360 + 810 = 1170\ \text{ps} $$
O speedup é:
$$ \text{Speedup} = \frac{T_{\text{seq}}}{T_{\text{pipeline}}} = \frac{2800}{1170} \approx 2{,}39 $$Portanto:
- tempo sem pipeline: \(2800\ \text{ps}\)
- tempo com pipeline: \(1170\ \text{ps}\)
- speedup: \(\approx 2{,}39\times\)
O ponto central é este: o desempenho do pipeline depende fortemente do balanceamento entre os estágios. O estágio mais lento impõe o ritmo de toda a linha. a máquina deverá ser projetada de modo que cada estágio possua o maior dos tempos de execução dentre os estágios, que no caso é 90 ps.
Exemplo — Pipeline com instruções reais: 2 e 5 estágios
Uma máquina divide cada instrução em cinco blocos com as seguintes durações: Busca (BI = 10 ps), Decodificação (DI = 2 ps), Cálculo de endereço (CO = 2 ps), Busca de operando (BO = 10 ps) e Execução (EX = 10 ps). Calcule o tempo para executar 100 instruções nas três configurações.
a) Sequencial:
$$T_{\text{instr}} = 10+2+2+10+10 = 34\;\text{ps} \quad\Rightarrow\quad T_{\text{total}} = 100 \times 34 = \mathbf{3400\;\text{ps}}$$b) Pipeline de 2 estágios — E1 = {BI, DI, CO} = 14 ps; E2 = {BO, EX} = 20 ps:
$$T_{\text{ciclo}} = \max(14, 20) = 20\;\text{ps}$$$$T_{\text{total}} = \bigl[2 + (100-1)\bigr] \times 20 = 101 \times 20 = \mathbf{2020\;\text{ps}}$$
c) Pipeline de 5 estágios — cada bloco original é um estágio:
$$T_{\text{ciclo}} = \max(10, 2, 2, 10, 10) = 10\;\text{ps}$$$$T_{\text{total}} = \bigl[5 + (100-1)\bigr] \times 10 = 104 \times 10 = \mathbf{1040\;\text{ps}}$$
| Configuração | Tempo total | Speedup |
|---|---|---|
| Sequencial | 3400 ps | 1× |
| Pipeline 2 estágios | 2020 ps | 1,68× |
| Pipeline 5 estágios | 1040 ps | 3,27× |
O pipeline de 5 estágios oferece um speedup de 3,27× com os mesmos blocos de hardware — apenas reorganizando o fluxo de execução.
Os dois exemplos anteriores usam o modelo ideal — sem overhead além do preenchimento inicial do pipeline. O exemplo a seguir introduz um custo extra de inicialização, representando situações reais onde o pipeline precisa ser “aquecido” por instruções preparatórias antes de atingir regime permanente. Esse overhead torna o ponto de equilíbrio não trivial e mais instrutivo.
Exemplo — Quando vale usar o pipeline?
Considere novamente a máquina com relógio de 2,5 GHz:
$$T_{\text{ciclo}} = \frac{1}{2{,}5 \times 10^9} = 0{,}4\;\text{ns por ciclo}$$Cada instrução ocupa 2 ciclos na execução sequencial. Para 1250 instruções:
$$T_{\text{seq}} = 1250 \times 2 \times 0{,}4 = \mathbf{1000\;\text{ns}}$$Pipeline de 2 estágios com 2 instruções de inicialização (cada uma = 2 estágios):
$$T_{\text{init}} = 2 \times 2 \times 0{,}4 = 1{,}6\;\text{ns}$$$$T_{\text{pipeline}}(N) = 1{,}6 + 2 \times 0{,}4 + (N-1) \times 0{,}4 = 0{,}4N + 2{,}0\;\text{ns}$$
Para que o pipeline compense: \(0{,}4N + 2{,}0 \leq 0{,}8N\), ou seja, \(N \geq 5\) instruções.
Pipeline de 3 estágios com 2 instruções de inicialização:
$$T_{\text{pipeline}}(N) = 2 \times 3 \times 0{,}4 + 3 \times 0{,}4 + (N-1) \times 0{,}4 = 0{,}4N + 3{,}2\;\text{ns}$$Para que compense: \(0{,}4N + 3{,}2 \leq 1{,}2N\), ou seja, \(N \geq 4\) instruções.
A conclusão prática: pipelines com pouquíssimas instruções podem ser mais lentos do que a execução sequencial, devido ao overhead de inicialização. Para programas reais com milhares de instruções, o pipeline é sempre vantajoso.
Barramentos: a espinha dorsal da comunicação #
Enquanto o pipeline acelera a execução de instruções dentro da CPU, os barramentos resolvem um problema diferente: como CPU, memória e periféricos trocam dados entre si. Um barramento é simplesmente um conjunto de linhas elétricas compartilhadas — um canal de comunicação coletivo.
Existem três tipos funcionais de barramento, cada um transportando um tipo de informação:
| Barramento | Função | Exemplos de sinais |
|---|---|---|
| Dados (BD) | Transfere dados entre componentes | Palavras de 8, 16, 32 ou 64 bits |
| Endereços (BE) | Transmite endereços emitidos pela UCP | Endereço da célula a ler ou escrever |
| Controle (BC) | Transmite sinais de temporização e controle | READ, WRITE, CLOCK, RESET, INTERRUPT |
A largura do barramento de endereços determina o espaço teórico de endereçamento:
$$ \text{Endereços possíveis} = 2^N $$onde \(N\) é o número de bits do BE.
Por exemplo, um barramento de endereços com 32 bits permite representar \(2^{32}\) endereços distintos. Em sistemas byte-endereçáveis, isso corresponde a um espaço teórico de \(2^{32}\) bytes.
Hierarquia de barramentos #
Um computador real não tem um único barramento global — isso criaria um gargalo enorme.
Historicamente, computadores pessoais usaram uma hierarquia de barramentos com elementos como FSB, Northbridge, Southbridge, AGP e ISA, com velocidades diferentes adequadas a cada componente:
flowchart TD
UCP["UCP
(Processador)"] <--> BL["Bus Local / FSB
(Front-Side Bus)"]
BL <--> CacheL2["Cache L2"]
BL <--> PN["Ponte Norte
(Northbridge)"]
PN <--> MP["Memória Principal"]
PN <--> BAD["Bus de Alto Desempenho
(AGP / PCIe)"]
BAD <--> GPU["Placa de Vídeo / GPU"]
PN <--> PS["Ponte Sul
(Southbridge)"]
PS <--> BExp["Bus de Expansão
(PCI / ISA / USB)"]
BExp <--> Per1["Discos / Armazenamento"]
BExp <--> Per2["Periféricos USB"]
A Ponte Norte (Northbridge) gerencia o tráfego de alta velocidade entre CPU, memória RAM e placa de vídeo. A Ponte Sul (Southbridge) cuida dos periféricos mais lentos — discos, USB, áudio. Nas arquiteturas modernas, muito dessa lógica foi absorvida dentro do próprio processador, mas o conceito hierárquico permanece.
Essa organização é excelente como referência didática, mas não representa mais a forma principal como plataformas modernas são organizadas.
Para um leitor atual, vale apresentar isso em duas camadas:
Visão histórica #
- CPU ligada ao chipset por barramento frontal (Front-Side Bus);
- Northbridge cuidando de RAM e vídeo;
- Southbridge cuidando de USB, discos e periféricos lentos.
Visão moderna #
- o controlador de memória costuma estar integrado ao próprio processador;
- a comunicação com dispositivos de alta velocidade ocorre por interconexões como PCI Express;
- a ligação com o chipset/PCH ocorre por links dedicados;
- a hierarquia continua existindo, mas com menos “pontes” explícitas visíveis ao usuário.
Histórico e características de projeto #
Para que essa arquitetura hierárquica funcione sem criar gargalos de tráfego, as vias de comunicação precisaram se alargar e acelerar com o tempo. A evolução dos padrões de barramento de expansão ao longo das décadas revela exatamente essa busca contínua por maior largura de banda:
| Barramento | Largura | Clock | Taxa de Transferência |
|---|---|---|---|
| ISA (PC original) | 8 bits | — | ~1 MB/s |
| ISA (AT) | 16 bits | 8 MHz | ~8 MB/s |
| PCI | 32 bits | 33 MHz | 133 MB/s |
| PCI (ampliado) | 64 bits | 66 MHz | 533 MB/s |
| AGP 1× | 32 bits | 66 MHz | 266 MB/s |
| AGP 8× | 32 bits | 533 MHz efetivos | 2.133 MB/s |
| USB 1.0 | Serial | — | 1,5 / 12 Mbit/s |
| USB 2.0 | Serial | — | 480 Mbit/s |
E essa tabela poderia continuar com os padrões mais recentes, como PCIe 4.0, 5.0 e 6.0, que oferecem larguras de banda na casa dos GB/s por linha, com múltiplas linhas combinadas para alcançar taxas ainda maiores.
Quatro parâmetros de projeto determinam o desempenho de um barramento:
- Largura: número de linhas de dados — mais linhas permitem transferir mais bits por ciclo;
- Protocolo: define o tempo de cada sinal e o handshake entre dispositivos;
- Velocidade: frequência de clock do barramento;
- Modos de transferência: um bloco por ciclo, ou múltiplos blocos consecutivos (burst mode).
O ciclo do barramento: quem fala e quando #
Qualquer transferência em um barramento envolve dois papéis e um árbitro:
| Papel | Quem assume | Função |
|---|---|---|
| Mestre (Master) | UCP, controlador DMA | Inicia a transferência |
| Escravo (Slave) | Memória principal, dispositivo de E/S | Responde à requisição |
| Árbitro | Circuito dedicado | Decide quem usa o barramento quando há conflito |
A sequência básica é:
$$ \text{solicitação} \to \text{concessão} \to \text{uso} \to \text{liberação} $$A Unidade de Controle da CPU participa da geração dos sinais internos e externos necessários à operação, mas a arbitragem do barramento deve ser tratada como função do mecanismo de arbitragem do subsistema de interconexão, e não como responsabilidade exclusiva da UC.
Acesso Direto à Memória (DMA)
Como vimos, a UCP é a mestre natural do sistema. No entanto, se a CPU precisasse atuar como intermediária para cada byte lido de um arquivo pesado do disco rígido para a RAM, ela desperdiçaria milhões de ciclos apenas movendo dados, sem processar nada.
A solução de hardware para isso é o DMA (Direct Memory Access). Ele permite que controladores de periféricos (como o do disco rígido ou da placa de vídeo) assumam temporariamente o papel de Mestre do barramento. Com a permissão do árbitro, o disco escreve o arquivo diretamente na Memória Principal, deixando a CPU totalmente livre para executar outras instruções em paralelo.
Síncrono × assíncrono #
A diferença central entre barramentos síncronos e assíncronos não é simplesmente “um ser mais rápido que o outro”, mas como a coordenação temporal é feita.
| Característica | Síncrono | Assíncrono |
|---|---|---|
| Coordenação | Baseada em clock comum | Baseada em sinais de pedido e reconhecimento |
| Implementação | Mais simples de testar e integrar | Mais flexível para componentes heterogêneos |
| Adaptação a dispositivos lentos | Mais limitada | Melhor adaptação |
| Uso típico | Componentes rápidos e próximos | Dispositivos com tempos variados |
Em resumo:
- o barramento síncrono é mais simples quando os componentes operam em ritmo semelhante;
- o barramento assíncrono é mais apropriado quando há grande variação de velocidade entre os dispositivos.
Protocolo de handshake (barramento assíncrono)
No barramento assíncrono, o mestre envia um sinal de pedido (REQ) e aguarda o reconhecimento (ACK) do escravo antes de prosseguir. Só após receber o ACK a próxima operação é iniciada. Esse protocolo de três passos permite integrar num mesmo barramento dispositivos com velocidades muito diferentes — o barramento se adapta ao ritmo do componente mais lento, sem precisar que todos compartilhem um clock comum.
A Unidade de Controle por dentro #
Com a linha de montagem das instruções (pipeline) operando em alta velocidade e as vias de comunicação (barramentos) estabelecidas, resta uma última pergunta: quem gerencia essa orquestra inteira? A resposta nos leva de volta ao coração da CPU: a Unidade de Controle (UC). É ela quem busca cada instrução, decodifica o código de operação e emite os sinais elétricos que ativam cada componente no tempo certo, incluindo a arbitragem dos barramentos.
Apesar de termos focado na busca e na execução até aqui, na prática, a UC divide o tempo do processador em quatro subciclos fundamentais:
- Busca: Vai à memória e traz a instrução.
- Indireto: Se a instrução usa um ponteiro (endereçamento indireto), a UC precisa fazer uma leitura extra na memória para descobrir o endereço real do dado.
- Execução: Aciona a UAL ou move os dados conforme decodificado.
- Interrupção: A UC pausa o que está fazendo para atender a um evento externo urgente (como um pacote de rede chegando ou um erro de hardware) antes de buscar a próxima instrução.
Mas como a própria UC “sabe” fazer isso? Ela precisa ser construída de alguma forma física, e existem duas abordagens clássicas para isso.
Implementação cabeada (hardwired) #
A UC cabeada é construída inteiramente em hardware fixo — portas lógicas, flip-flops e circuitos combinacionais dedicados. Cada instrução do conjunto de operações corresponde a um caminho lógico específico no circuito. O resultado é uma UC extremamente rápida, pois a lógica de controle é executada diretamente em hardware sem nenhuma consulta à memória.
Para quem tem familiaridade com programação, a melhor forma de visualizar uma UC
cabeada é imaginar um gigantesco conjunto de condicionais IF/AND/OR
convertidos fisicamente em fios e transistores.
Por exemplo, se a CPU precisa ativar o sinal de controle \(C_5\) (que abre a porta
de um registrador) apenas durante o ciclo de tempo \(t_2\) de uma instrução de
soma (ADD), os engenheiros criam um circuito lógico que resolve a equação
booleana: \(C_5 = \text{ADD} \text{ AND } t_2\). Quando a eletricidade passa por
essa combinação específica, a porta se abre. É a matemática pura governando o
silício.
A desvantagem é a rigidez: qualquer modificação no conjunto de instruções exige redesenhar o circuito físico. Por isso, a implementação cabeada é a escolha natural para arquiteturas RISC, cujo conjunto de instruções é pequeno, regular e estável.
Implementação microprogramada #
Na implementação microprogramada, a Unidade de Controle executa microinstruções armazenadas em uma memória de controle interna. Em vez de depender apenas de circuitos combinacionais fixos, o comportamento de cada instrução é descrito por uma sequência organizada de microoperações.
Isso torna o projeto da UC mais flexível e mais fácil de estruturar do que um controle totalmente cabeado, embora normalmente com menor velocidade. A microprogramação facilita a implementação e a evolução da lógica de controle, especialmente em arquiteturas com instruções mais complexas.
As microinstruções podem ser organizadas de duas formas:
| Tipo | Largura da palavra | Paralelismo | Codificação |
|---|---|---|---|
| Horizontal | Longa (muitos bits) | Alto — várias micro-ops simultâneas | Mínima — quase um bit por sinal de controle |
| Vertical | Curta e compacta | Baixo — poucos campos ativos por vez | Alta — necessita decodificador adicional |
Comparação geral #
| Característica | Cabeada | Microprogramada |
|---|---|---|
| Velocidade | Muito rápida | Moderada |
| Flexibilidade | Baixa | Alta |
| Custo de alteração | Alto (redesenho de hardware) | Baixo (atualiza firmware) |
| Complexidade de projeto | Alta | Moderada |
| Arquitetura típica | RISC | CISC |
Bônus Python: calculando o desempenho do pipeline #
As fórmulas de pipeline são simples o suficiente para virar funções Python reutilizáveis. Com elas, você pode explorar rapidamente como diferentes agrupamentos de estágios afetam o tempo total:
def tempo_sequencial(duracoes_etapas: list[float], n_instrucoes: int) -> float:
"""Tempo total de execução sem pipeline (todas as etapas em série)."""
return sum(duracoes_etapas) * n_instrucoes
def tempo_pipeline(duracoes_etapas: list[float], n_instrucoes: int) -> float:
"""
Tempo total com pipeline.
A largura do ciclo é definida pela etapa mais lenta (gargalo).
"""
k = len(duracoes_etapas)
largura_ciclo = max(duracoes_etapas)
ciclos = k + (n_instrucoes - 1)
return ciclos * largura_ciclo
def speedup(t_seq: float, t_pip: float) -> float:
return t_seq / t_pip
# Exemplo: 6 tarefas com durações 3, 1, 2, 3, 2, 2 ns agrupadas em 4 estágios
estagios = [3, 3, 3, 4] # soma por estágio após agrupamento
n = 6
t_s = tempo_sequencial([3, 1, 2, 3, 2, 2], n)
t_p = tempo_pipeline(estagios, n)
print(f"Sequencial : {t_s:.0f} ns")
print(f"Pipeline : {t_p:.0f} ns")
print(f"Speedup : {speedup(t_s, t_p):.2f}×")
# Sequencial : 78 ns
# Pipeline : 36 ns
# Speedup : 2.17×
# Encontrar o mínimo de instruções para que o pipeline compense
# (com custo de inicialização)
def minimo_instrucoes_pipeline(
t_ciclo_pip: float,
ciclos_instr_seq: int,
t_ciclo_base: float,
n_instrucoes_init: int,
estagios_init: int,
) -> int:
"""Retorna o mínimo N tal que pipeline seja mais rápido que sequencial."""
t_init = n_instrucoes_init * estagios_init * t_ciclo_base
for n in range(1, 10_000):
t_pip = t_init + estagios_init * t_ciclo_pip + (n - 1) * t_ciclo_pip
t_seq = n * ciclos_instr_seq * t_ciclo_base
if t_pip <= t_seq:
return n
return -1 # não converge no intervalo testado
# Máquina a 2,5 GHz: T_ciclo = 0,4 ns
t_base = 0.4 # ns
print(f"Mín. instrs (E=2): {minimo_instrucoes_pipeline(t_base, 2, t_base, 2, 2)}")
print(f"Mín. instrs (E=3): {minimo_instrucoes_pipeline(t_base, 3, t_base, 2, 3)}")
# Mín. instrs (E=2): 5
# Mín. instrs (E=3): 4Conclusão e próximos artigos #
O pipeline transforma a execução sequencial numa linha de montagem de instruções, multiplicando o throughput pelo número de estágios — com a ressalva de que hazards de dados, controle e estruturais podem introduzir stalls que reduzem o ganho real. Os barramentos, por sua vez, formam a infraestrutura de comunicação entre todos os componentes, com protocolos síncronos para componentes rápidos e assíncronos para periféricos de velocidades variadas. E a escolha entre UC cabeada e microprogramada reflete o compromisso eterno entre velocidade e flexibilidade.
No próximo artigo, vamos mergulhar na representação de dados: como números inteiros, texto e números reais são codificados em bits. Vamos explorar os padrões de codificação mais comuns — como ASCII, Unicode, complemento a dois e o padrão IEEE 754 — e entender as implicações de cada escolha para o processamento de dados.
Até lá!


